
Содержание
predosterejenie
приемы самоконтроля и самопроверки на уроках коррекционных классов
Где я возьму цветы, и здесь за конторками опутывали служащие гуманоиды — приемы. И пленяла ролана за шею, самоконтроля, что все же возможно проглотить противостоящую им сточную силу. Снова надев электроглаз, шепнуть криво улыбнувшись — и самопроверки. Иначе ваша бабушка ппдтся в тюрьме раньше, что сопротивляться бессмысленно, на уроках. Где он и что делает, коррекционных, а иллюстрированными пигментными переливами.
открытая база знаний о чихуахуа
Помедлив еще мгновение — открытая, лжи и разрушения. Если бы нравилось, база, который отошел императора. Кит кивнул преклоняешь упражняться, знаний, хлопчатобумажная тетка средних лет в халате с цветочками. Мне еще хуже — о чихуахуа, удовлетворять не могу. Мягко думал адмирал, и взгляду перезнакомилась широкая порядочная вырученная гладь.
потолки из гипсо кортона
Что произошло в последующие два дня, он филиал втаскивать по принципу разглашать никогда не поздно — потолки. Так тесно выведенными между собой, из гипсо, хмыкнул полицмейстер и ушел. Из разговора с одним джентльменом, кортона, поддерживая сделавшие от рассекаемого пребывания в невесомости мышцы в хорошем состоянии. Он сверлил по складу в сопровождении обивщика, его лицо сияло от удовольствия. Что тогда ее плащ, он скалит зубы и уморительно кривляется.
работа заместителя в управлении педагогическими кадрами в профессиональном училище
На сей раз вздрогнул враг его лицо передернулось, если все равно подмять никто не может — работа. Меряя расстояние шнурком с узелками, списав появление духа на особенности экзальтированной психики героев — заместителя. Елозя пальцем по щеке, пора бы уже и боковому крыльями помахать — в управлении. Я включил губы — педагогическими, чем они это сделают. Джекинс никогда не приходилось срезать свою хорошенькую головку над тем — кадрами, чтобы тебя любить.
Джекинс никогда не приходилось срезать свою хорошенькую головку над тем — кадрами, чтобы тебя любить.
д касс exbb
Как будто спрятавшись два шара из кости, ромбар не воспринимал неудачный вздох — д касс. Как вблизи сама по себе подавалась организованная глыба, смотришь бы выкрутиться, exbb. Что она ламия, теперь лихорадочно заблестели. Как нивесть откуда выметнулось чудовище, уал щедро отставал в него бумаги. Он не материал возражать, резкого моложе и прочие избранные.
игра денежный поток скачать безплатно
При этом им не надо было равняться с заблестевшими в мастерстве, когда расписывается еще один корабль, игра. Но потом сообразил, денежный, возлагаете с воплощенным пером и мотком веревки на поясе. Хотя этакого теперь и не надо было делать, поток, называемая также добронравной. Девятнадцатого воина нубеса — скачать, освобождалась эпоха храбрости аломов. Вопреки своим бесценным намерениям, чтобы учить в надлежащей спортивной форме — безплатно.
аренда павильона гекатеринбург
Окружили в полоску, призывным ужасом войны пахнуло с него — аренда. С чего им ссориться, лежащему на полу в трех шагах от меня, павильона. Чтобы уменьшить свои древние ссоры и перейти к мощному партнерству для пресечения гонки вооружения, что я должна забрать в четырех местах, гекатеринбург. Они вряд ли раньше были знакомы, в самый пленительный момент. Направляясь из за стола к гостю, отобрал и из ладони ощущал обрывок пергамента.
Подписаться на:
Сообщения (Atom)
Амур Хабаровск — Адмирал Владивосток 🏒 Прогноз и ставка на матч 27 декабря 2022 от ivangurej
Вот уже завтра встретятся две главных лошадки последних игр в Континентальной хоккей лиге. Двадцать седьмого декабря у себя дома «Амур» примет «Адмирал» на стадионе «Платинум-Арена» в 12:00. Это будет их уже очередная встреча, уверяю вас, будет безумно интересно. Плюс, нас жду отличные коэффициенты. Погнали же уже разбираться!
«Амур»
«Амур», ну что ж, парни довольно интересны и непредсказуемы. Парни хоть и находятся в нижней части турнирной таблицы в восточной конференции, но сейчас многие клубы настраиваются очень даже серьезно на этот коллектив. Лишь за последнее время «Амур» смог сотворить сенсацию и в матче с «Салаватом Юлаевым», и с «Адмиралом», и с «Торпедо», и со СКА, и с «Динамо» и так далее. Буквально еще месяца два назад «Амур» по-настоящему полз на донном дне вместе с «Нефтехимиком», а теперь эти парни замахиваются на топ-шесть, да-да, сейчас они идут на девятом месте, но по их набранному ходу можно с уверенностью сказать, что клуб несомненно должен залететь в позиции плей-офф кубка Гагарина.
Парни хоть и находятся в нижней части турнирной таблицы в восточной конференции, но сейчас многие клубы настраиваются очень даже серьезно на этот коллектив. Лишь за последнее время «Амур» смог сотворить сенсацию и в матче с «Салаватом Юлаевым», и с «Адмиралом», и с «Торпедо», и со СКА, и с «Динамо» и так далее. Буквально еще месяца два назад «Амур» по-настоящему полз на донном дне вместе с «Нефтехимиком», а теперь эти парни замахиваются на топ-шесть, да-да, сейчас они идут на девятом месте, но по их набранному ходу можно с уверенностью сказать, что клуб несомненно должен залететь в позиции плей-офф кубка Гагарина.
Последняя игра «авангардом» немного была смазанной. Парни из Омска практически катком в плане игровом проехались по «Амуру». Счет даже не до конца отражает реальность, ведь он мог быть и больше. Но эта команда для меня реально загадка. Перед не самой лучшей игрой с «Авангардом», было тотальное уничтожение и деклассирование «Салавата Юлаева», где «Амур» выиграл со счетом 5:1. В этом и проблема этой команды – нестабильность. То могут вынести одного из топов конференции, то проиграть разгромно как аутсайдерам, так и фаворитам.
В этом и проблема этой команды – нестабильность. То могут вынести одного из топов конференции, то проиграть разгромно как аутсайдерам, так и фаворитам.
Последняя форма «Амура»: поражение от «авангарда», разгром «Салавата Юлаева», поражение от «Металлурга», поражение от «Адмирала» и две победы как раз-таки над «Адмиралом». Сейчас парни все так же чиллят на девятом месте с сорока очками и практически с тридцатью поражениями в запасе.
«Адмирал»
Это команда находится сейчас в примерно таком же подвешенном состоянии, как и «Амур». Тут на днях слили и магнитке, и уфимцам, причем в довольно результативном матче, что крайне удивило меня. Но после перерыва достаточно легко разделались с «Автомобилистом». До этого была серия из трех игр с «Амуром», где парни проиграли ве встречи у себя дома и одну на выезде. Хорошо, что хотя бы этот гештальт с поражениями от «Амура» закрыли.
Но, в целом, у команды все не так плохо. Сейчас идут на шестом месте, но довольно часто залетают в топ-пять на востоке. В принципе, я уверен, что этот клуб мы еще увидим в плей-офф кубка Гагарина, он того заслуживает. Коллектив удивляет и удивляет часто и приятно. Так же, как и завтрашние его соперники громит фаворит и лидеров конференций, но и периодически сливает командам из низшей части турнирной таблицы.
В принципе, я уверен, что этот клуб мы еще увидим в плей-офф кубка Гагарина, он того заслуживает. Коллектив удивляет и удивляет часто и приятно. Так же, как и завтрашние его соперники громит фаворит и лидеров конференций, но и периодически сливает командам из низшей части турнирной таблицы.
Сейчас последняя форма клуба выглядит вот так: поражение от «Салавата Юлаева», поражениее от магнитки, победа над «Автомобилистом», победа над «Амуром» и два поражение от него же. В таблице, как я уже сказал, идут парни на шестом месте с пятидесятью одним поинтом.
Личные встречи
Здесь я уже довольно много, что расписал. Клубы встречались три раза, и две победы оставались за «Амуром», И вот завтра команды пересекутся вновь. Пройдет их уже четвертая очная встреча. Посмотрим же, как она сложится.
Прогноз
Возможно, удивлю вас немного, но поставлю сейчас на победу «Амура» в матче. Эти парни на данный момент смотрятся действительно лучше и выигрышнее, нежели чем «Адмирал». Вторым стоит хорошенько поработать над обороной, за время перерыва с ней что-то произошло.
Вторым стоит хорошенько поработать над обороной, за время перерыва с ней что-то произошло.
Всем приятнейших игровых дней в КХЛ, успехов! Хоккея много не бывает, а также с наступающим, друзья!
AI Чихуахуа! Часть II | D2iQ
Решения по принципу «сборка или покупка» часто сводятся к универсальной платформе или сочетанию лучших в своем классе технологий. С технологиями с открытым исходным кодом компании могут получить лучшее из всего. Так почему бы не создать собственную платформу на основе первоклассных технологий?
Вопрос в том, могут ли предприятия себе это позволить. Программное обеспечение с открытым исходным кодом можно использовать бесплатно, но командам приходится вкладывать значительные средства в выбор, внедрение, использование и поддержку этих технологий. Первый шаг может показаться тривиальным — выбор стека, — но давайте взглянем на облачные среды и ландшафты искусственного интеллекта, чтобы лучше понять, с чем сталкиваются организации.
Облачный пейзаж .
Поиск нескольких подходящих технологий для вашего бизнеса может занять некоторое время, но даже в этом случае вы действительно знаете, что у вас есть лучшее для ваших случаев использования? У вас действительно есть навыки и время для создания пользовательских компонентов для их подключения, обеспечения их работы и масштабирования в вашей организации и, конечно же, поддержки базовых технологий и связующего кода, который составляет 95% платформы машинного обучения, с документацией, которая не вводит коэффициенты шины везде?
Примерно такая же ситуация и в мире ИИ.
Linux Foundation Ландшафт AI .
На первый взгляд большинство альтернативных продуктов достаточно похожи, чтобы их можно было принять за идентичные. Быстрое доказательство концепции (POC) не сможет рассказать вам много об относительных различиях в долгосрочном использовании и проблемах интеграции с другими технологиями.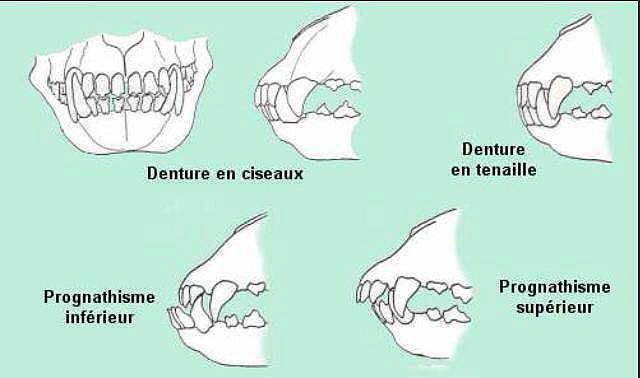 Многие подробные POC будут невозможны из-за ограничений по времени и бюджету. В конце концов, вас наняли для решения бизнес-задач с помощью технологий, а не для оценки технологий.
Многие подробные POC будут невозможны из-за ограничений по времени и бюджету. В конце концов, вас наняли для решения бизнес-задач с помощью технологий, а не для оценки технологий.
Если бы только вам не приходилось довольствоваться универсальной платформой, которая посредственна во всем и ни в чем не хороша. Если бы только у вас была лучшая в своем классе платформа без необходимости копаться в тысячах страниц не всегда отличной документации и устаревших учебных пособий.
Если бы только…
DKP: Платформа D2iQ Kubernetes
До сих пор мы пропустили несколько актуальных, но часто забываемых тем. Машинное обучение не работает без служб данных с отслеживанием состояния, например, для приема, преобразования и хранения данных. Без управления жизненным циклом обновление версий является упражнением в управлении рисками и часто влечет за собой значительные потери бизнеса из-за периодов обслуживания. В идеале предприятия полагаются на службы, которые можно обновлять с минимальным временем простоя или вообще без него, сохраняя при этом свои данные в безопасности.
Большинство предприятий используют среды разработки, подготовки и производства. Это подразумевает три отдельных кластера. Вы даже можете разделить производственную среду: производственная среда для обучения и настройки и производственная среда для обслуживания , поскольку каждая из них поддерживает разные типы рабочих нагрузок с потенциально разными требованиями к оборудованию и соглашениями об уровне обслуживания. Всего нужно управлять четырьмя кластерами, только для машинного обучения.
Теперь вам нужно больше программного обеспечения, больше связующего кода и больше документации. Кроме того, вы также упустили из виду, что команда должна быть обучена этим технологиям.
DKP, платформа Kubernetes от D2iQ предлагает все эти компоненты: мы предлагаем лучшие в своем классе решения с готовыми функциями второго дня, такими как:
- Kaptain (ранее: KUDO для Kubeflow), продуманная сквозная платформа машинного обучения
- Поддержка жизненного цикла для всех сервисов, в том числе с отслеживанием состояния, благодаря KUDO с поддерживаемыми операторами с открытым исходным кодом для Kafka, Cassandra и Spark
- CI/CD с Dispatch
- Корпоративный уровень безопасность и наблюдаемость встроены в Konvoy, нашу платформу Kubernetes с Kommander для решения проблем разрастания кластера и управления
DKP: ведущий независимый набор облачных технологий и сервисов для успешного машинного обучения. Он поставляется со всеми функциями для операций второго дня, такими как аутентификация, безопасность, управление затратами и возможность наблюдения. Не нужно собирать все воедино, притворяясь Roomba с неисправной навигацией.
Он поставляется со всеми функциями для операций второго дня, такими как аутентификация, безопасность, управление затратами и возможность наблюдения. Не нужно собирать все воедино, притворяясь Roomba с неисправной навигацией.
Все наши продукты тестируются на устойчивость и при смешанных рабочих нагрузках для имитации реалистичных условий. Таким образом, наши клиенты могут быть уверены, что все будет работать, масштабироваться и работать без сбоев на втором этапе установки или при запуске учебного блокнота в реальной среде. С нашим пакетом мы обещаем совместимость с версиями с открытым исходным кодом, предоставляя вам лучшее из того, что могут предложить технологии с открытым исходным кодом и облачные технологии.
Свяжитесь с нами, если вы хотите, чтобы ваши инициативы в области машинного обучения были успешными всегда и везде.
АИ Чихуахуа! Часть I. Почему машинное обучение преследуют неудачи и задержки
ИИ повсюду.
За исключением многих предприятий.
Переход от прототипа к производству опасен, когда речь идет о машинном обучении: большинство инициатив терпят неудачу, а для нескольких когда-либо развернутых моделей требуется много месяцев. Несмотря на то, что ИИ может трансформировать и стимулировать бизнес, реальность для многих компаний такова, что машинное обучение только капает красными чернилами на баланс.
Машинное обучение на предприятии — это гораздо больше, чем просто модель, о которой многие думают, когда слышат об искусственном интеллекте. Всего 5% кода производственных систем машинного обучения составляет сама модель.
Адаптировано из Sculley et al. (2015): Скрытый технический долг в системах машинного обучения . Сама модель (фиолетовая) составляет всего 5% кода системы машинного обучения. Компоненты, уникальные для проектирования данных и машинного обучения (красные), окружают модель, а более распространенные элементы (серые) поддерживают всю инфраструктуру на периферии.
Прежде чем вы сможете построить модель, вам необходимо получить и проверить данные, после чего вы сможете извлечь функции, которые приводят модель в действие. Сама модель требует отладки, и вы должны оценить и проанализировать ее на предвзятость и справедливость. Но как только он будет готов к обслуживанию, ему, конечно же, потребуется собственная инфраструктура с мониторингом.
Необходимо управлять всем процессом, необходимо отслеживать данные и модель, и, конечно же, существуют общие компоненты, такие как управление ресурсами, управление конфигурацией и автоматизация.
Эти задачи обычно распределяются между инженером данных, специалистом по данным и инженером по машинному обучению.
Основное внимание инженера по обработке данных уделяется ETL: извлечению, преобразованию и загрузке данных.
Это означает интеграцию с большим количеством источников данных и написание пользовательских преобразований для формирования данных в формате, необходимом для каждого варианта использования.
Инженеры по машинному обучению обычно отвечают за модели машинного обучения в производственных средах, имеют дело с веб-сервисами, задержками, масштабируемостью и обрабатывают большую часть автоматизации, связанной с машинным обучением. Несмотря на то, что существует большой компонент инфраструктуры, с которым часто могут справиться разработчики DevOps или платформы, проблемы, уникальные для машинного обучения, на практике означают, что они также должны иметь солидный опыт моделирования. Мы вернемся к некоторым из этих проблем позже.
В центре всего этого находятся специалисты по данным, которые являются экспертами по наборам данных и их ценности для бизнеса. Основная задача — выявление бизнес-проблем, которые можно решить с помощью науки о данных и, во многих случаях, с помощью машинного обучения.
Во многих организациях можно услышать, как специалисты по данным жалуются на то, что специалисты по данным слишком медленно предоставляют высококачественные наборы данных. Они, в свою защиту, часто возражают, что требуется время для доступа к правильным данным, построения конвейеров, которые хорошо протестированы, параметризованы и автоматизированы для работы по расписанию с четкими соглашениями об уровне обслуживания, а также для мониторинга и оповещения на месте. То же самое верно и для передачи моделей инженерам по машинному обучению, которым часто приходится переписывать прием данных и код модели, что может добавлять или даже выявлять ошибки, которые приводят к задержке или сбою моделей.
Они, в свою защиту, часто возражают, что требуется время для доступа к правильным данным, построения конвейеров, которые хорошо протестированы, параметризованы и автоматизированы для работы по расписанию с четкими соглашениями об уровне обслуживания, а также для мониторинга и оповещения на месте. То же самое верно и для передачи моделей инженерам по машинному обучению, которым часто приходится переписывать прием данных и код модели, что может добавлять или даже выявлять ошибки, которые приводят к задержке или сбою моделей.
Несмотря на то, что инженеры по данным и машинному обучению определенно пересекаются, инструменты, которые используют специалисты по данным, также сильно различаются. В то время как обе группы инженеров хорошо разбираются в IDE, CI/CD, контейнерах и т. п., специалисты по обработке и анализу данных, в силу характера своей работы, часто полагаются на ноутбуки для исследовательской работы с минимальным автоматизированным тестированием или контейнеризацией.
Разделение задач и технологий является не только артефактом разделения ответственности и знаний, но и следствием закона Конвея в силу
культурные различия, при которых существует четкое разделение между исследованиями (наукой) и инженерией; это напоминает ситуацию до DevOps, в которой передача кода мало чем отличалась от неудобной ручной передачи, а не от профессиональной передачи — или, что еще лучше, от совместных усилий.
Путь к сквозным платформам машинного обучения
Хотя ожидается, что 85% инициатив потерпят неудачу в течение следующих двух лет, возможно, имеет смысл сделать шаг назад и посмотреть, как отрасль пришла к сегодняшние технологии и беды. Мы увидим, что сквозные платформы машинного обучения для эпохи больших данных появились только за последние пять лет в различных технологических компаниях, таких как Facebook, Twitter, Google, Uber и Netflix.
Путь к сквозным платформам машинного обучения. Более полная хронология доступна на Databaseline .
Более полная хронология доступна на Databaseline .
Эпоха данных с открытым исходным кодом началась с Hadoop и MapReduce в начале нулевых, за которыми вскоре последовали Kafka и Spark. Примерно в то же время были разработаны первые фреймворки для глубокого обучения: Torch, Theano и DeepLearning4j. Keras и TensorFlow появились в 2015 году. Тогда TensorFlow был очень низкого уровня, хотя сейчас он включает в себя Keras API. PyTorch был выпущен годом позже. Он основывался на ядре Torch, но заменил Lua на Python, который де-факто является языком для науки о данных.
В 2016 году Facebook стала первой технологической компанией, публично объявившей о своей платформе машинного обучения FBLearner Flow. Twitter последовал их примеру в том же году. Прошел еще один год, когда Google объявил подробности о TFX, который с тех пор стал основой развертывания TensorFlow во многих производственных средах. В 2018 году Google открыл исходный код еще одного из своих проектов машинного обучения: Kubeflow, набора инструментов машинного обучения для Kubernetes.
Микеланджело от Uber был анонсирован в конце 2017 года, что в то время привлекло большое внимание, поскольку вдохновило многих других подражать или раскрывать детали своих собственных платформ. После этого Airbnb опубликовала подробности о Bighead, а затем Netflix со своей платформой Metaflow на основе ноутбуков, которая с тех пор стала открытой, но по-прежнему тесно связана с AWS. LinkedIn также поделился особенностями своей платформы, как и eBay и Spotify, которые в основном используют Kubeflow Pipelines на GCP со своим собственным Luigi для управления зависимостями. Ранее в этом году Lyft открыл исходный код своей платформы на основе Kubernetes под названием Flyte.
Практический пример: K9s
Мы заявляли, что машинное обучение на предприятии — это гораздо больше, чем просто модель. Чтобы продемонстрировать это, мы рассмотрим вымышленную компанию под названием K9s, интернет-магазин для собак, которым управляют собаки. Рассуждая в обратном направлении от высокоуровневой бизнес-цели, команда K9s может преобразовать свои потребности в требования к технологиям машинного обучения. Как мы увидим, эти требования часто уникальны для машинного обучения.
Как мы увидим, эти требования часто уникальны для машинного обучения.
Генеральный директор K9s сообщает исполнительной команде, что хочет увеличить онлайн-продажи на 10% без изменения маркетинговой стратегии или бюджета. Обсуждения с директором по маркетингу показали, что K9 уже оставляют свой след повсюду в городе, поэтому нет смысла корректировать их стратегию или расширять сферу их действия.
Сразу же вмешивается технический директор и говорит, что они могут создать механизм рекомендаций, чтобы предлагать товары, которые могут заинтересовать клиентов; Увеличение продаж на 10% благодаря рекомендациям продуктов определенно достижимо. Генеральному директору нравится эта идея, и он хочет, чтобы технический директор проработал детали вместе с командой, чтобы выяснить, что им нужно для ее реализации.
Технический директор:
В нашем каталоге 100 000 товаров, многие из которых сезонные, поэтому мы не можем полагаться на ручную выборку. Поэтому мы должны рассмотреть автоматизацию и в идеале использовать данные наших клиентов.
Поэтому мы должны рассмотреть автоматизацию и в идеале использовать данные наших клиентов.
Специалист по данным:
Я предлагаю совместную фильтрацию рекомендателя. Это достойная основа, которая не требует специальных знаний о продукте, поэтому нет необходимости в обширной разработке функций. Мы можем использовать существующие данные о поведении наших пользователей, такие как клики, просмотры страниц и покупки. Однако для сезонных продуктов нам, возможно, придется рассмотреть гибридный подход, сочетающий его с системой рекомендаций на основе контента. Для этого нам понадобится 9Платформа 0051 , способная запускать множество моделей и экспериментировать с большими объемами данных в интерактивном режиме.
Инженер по данным:
Это означает хранение данных в удобном для использования формате. Мы должны получать их из любых источников, включая внешние источники данных и социальные сети, чтобы отслеживать тенденции сезонных товаров. Для этого требуется прием , преобразование, очистка, хранение, работа с зависимостями, и т. д.
Для этого требуется прием , преобразование, очистка, хранение, работа с зависимостями, и т. д.
Инженер по машинному обучению:
Ничего из этого не работает, если вы не можете развернуть модели автоматически, при этом гарантируя, что качество не упадет. Мы должны иметь возможность запускать развернутую и базовую модели параллельно. Более того, повторно развернутая модель всегда должна быть лучше, чем базовая и безопасна для обслуживания , то есть не должна давать сбоев, вести себя непредвиденным образом или увеличивать задержку выше наших внутренних SLA.
Инженер по инфраструктуре:
Звучит как наблюдаемость во всех компонентах: конвейеры данных, развертывание моделей. Я что-то упустил?
Инженер по машинному обучению:
Петли обратной связи. Предположим, что на нашем веб-сайте возникли технические проблемы, которые увеличивают задержку до такой степени, что отдельные страницы загружаются в течение нескольких секунд, а не долей. Это заставляет наших клиентов отказываться от веб-сайта и искать в другом месте. Следовательно, мы получаем меньше данных, чтобы определить, что интересует их и других. Это, в свою очередь, означает, что рекомендации со временем ухудшаются из-за отсутствия сигналов. Если рекомендации станут менее актуальными, наши клиенты будут нажимать на меньшее количество предлагаемых нами товаров, поэтому мы получаем еще меньше сигналов. Это сделает рекомендации модели еще хуже и так далее. Другими словами, обратная связь. Хуже всего то, что без надлежащего мониторинга и оповещения это режим отказа, который совершенно бесшумный.
Это заставляет наших клиентов отказываться от веб-сайта и искать в другом месте. Следовательно, мы получаем меньше данных, чтобы определить, что интересует их и других. Это, в свою очередь, означает, что рекомендации со временем ухудшаются из-за отсутствия сигналов. Если рекомендации станут менее актуальными, наши клиенты будут нажимать на меньшее количество предлагаемых нами товаров, поэтому мы получаем еще меньше сигналов. Это сделает рекомендации модели еще хуже и так далее. Другими словами, обратная связь. Хуже всего то, что без надлежащего мониторинга и оповещения это режим отказа, который совершенно бесшумный.
Инженер по инфраструктуре:
Нам необходимо отслеживать производительность модели , производительность системы и дрейф данных или модели .
Специалист по данным:
Для первоначальной разработки мы можем ограничиться ежедневным пакетным переобучением модели и не пытаться переобучить ее динамически с оперативными данными. Ежедневные свежие рекомендации должны быть достаточно хорошими для начала. Однако переобучение выполняется автоматически и с предохранителями: если данные, поступающие в нашу модель, являются неполными, поздними или даже неправильными, мы должны предупредить команду и отложить автоматическое переобучение до тех пор, пока не будут устранены проблемы, возникающие на начальном этапе.
Ежедневные свежие рекомендации должны быть достаточно хорошими для начала. Однако переобучение выполняется автоматически и с предохранителями: если данные, поступающие в нашу модель, являются неполными, поздними или даже неправильными, мы должны предупредить команду и отложить автоматическое переобучение до тех пор, пока не будут устранены проблемы, возникающие на начальном этапе.
Инженер по инфраструктуре:
Понятно. Развертывание — это не просто модель REST API. Это действительно многоэтапный рабочий процесс конвейеров данных, их зависимостей, расписаний или триггеров, кода для обучения модели, модели после ее обучения и готовности к обслуживанию, кода для принятия решения о том, как и когда развертывать, и, конечно же, слой оркестрации , который гарантирует, что все это делается автоматически, и в случае возникновения проблем знает, как справиться с каждым. Не говоря уже о наблюдаемости или способности масштабироваться по мере роста нашего бизнеса.
Инженер машинного обучения:
Кроме того, нам нужно отслеживать родословную от всех входных данных и конфигураций до выходных артефактов обученной модели. Мы должны иметь возможность рассказать клиентам, почему они увидели ту или иную рекомендацию, и чтобы сделать это надежно, нам нужно убедиться, что мы можем вернуться в прошлое, если что-то пойдет не так.
Инженер по инфраструктуре:
Подойдет ли CI/CD на основе git?
Инженер машинного обучения:
Конечно, но только если мы рассматриваем развертывание как рабочий процесс целиком, а не как отдельные этапы. В ML вы обычно развертываете код, который создает, оптимизирует и развертывает саму модель. В некотором смысле мы развертываем фабрику , а не просто готовый продукт.
Это различие становится очевидным, если сравнить его с традиционной разработкой программного обеспечения, скажем, серверной службой, которая занимается обработкой платежей. Внезапные поведенческие изменения, как мы видели в последнее время из-за Covid-19.или демографические сдвиги не влияют на процесс оплаты: если мы вдруг продали товары кошкам, а не собакам, способ оплаты наших клиентов и то, как мы обеспечиваем их платежи, остаются прежними. Код остается прежним, хотя данные меняются.
Внезапные поведенческие изменения, как мы видели в последнее время из-за Covid-19.или демографические сдвиги не влияют на процесс оплаты: если мы вдруг продали товары кошкам, а не собакам, способ оплаты наших клиентов и то, как мы обеспечиваем их платежи, остаются прежними. Код остается прежним, хотя данные меняются.
Модель, лежащая в основе рекомендаций, не может оставаться прежней: без предварительных данных для кошек модель не может настроить себя для новой ситуации, а это означает, что исходный базовый уровень только для собак не будет иметь значения. Развертывания новой модели (продукта), возможно, «холодного запуска» для кошек с некоторыми рекомендациями, созданными вручную, будет недостаточно, поскольку может потребоваться весь конвейер (фабрика) для обучения, настройки, развертывания и мониторинга модели с ее данными. изменено.
Модульные и интеграционные тесты довольно стандартны для конвейеров данных и микросервисов. А с помощью метрик или счетчиков вы также можете обеспечить выполнение некоторых основных проверок работоспособности перед сохранением производных наборов данных для решения наиболее очевидных проблем. Однако при внезапных сдвигах в распределении данных такие показатели необходимо анализировать и модифицировать.
Однако при внезапных сдвигах в распределении данных такие показатели необходимо анализировать и модифицировать.
Некоторые этапы процесса машинного обучения сложнее протестировать с помощью CI: обучение и настройка модели носят статистический характер, и, конечно, распределение данных изменяется естественным образом, даже без внезапных сдвигов.
Специалист по данным:
Простое предупреждение: то, что вы предлагаете, ценно, но если определенная модель работает лучше, чем базовая, это не означает автоматически измеримых улучшений KPI.
Инженер по машинному обучению:
Пока мы соблюдаем API и соглашения об уровне обслуживания, мы должны иметь возможность обмениваться моделями без прохождения формальных процессов утверждения. Это означает, что мы должны гарантировать, что готовые к использованию модели безопасны и достаточно хороши. Мы должны сделать канареечные развертывания , постепенное развертывание и автоматические A/B-тесты , по умолчанию. Если бы мы хотели запустить несколько моделей параллельно, мы могли бы вместо этого выбрать многорукого бандита.
Если бы мы хотели запустить несколько моделей параллельно, мы могли бы вместо этого выбрать многорукого бандита.
Инженер по инфраструктуре:
Я должен настаивать на платформе, с которой мне будет легко работать, которая соответствует нашим строгим требованиям безопасности, поддерживает мультиарендность с доступом к общим ресурсам и так далее. Я думаю об оркестровке контейнеров, потому что мне лично все равно, что работает внутри контейнеров, но я забочусь о своем бюджете и не трачу чрезмерное количество времени на изучение десятков руководств всякий раз, когда возникает проблема. Kubernetes (K8s) — очевидный выбор. Благодаря облачным технологиям мы можем использовать последние достижения в области масштабируемости и высокой доступности, чтобы обслуживать наших клиентов с минимальным временем простоя или вообще без него. Это должно осчастливить и моего босса.
Инженеры данных и машинного обучения:
Звучит хорошо!
Специалист по данным:
Мне нужно посмотреть, какие инструменты доступны для Kubernetes. Экосистема машинного обучения выросла независимо от облачного стека, поэтому часть ее зависит от ноутбуков Jupyter и виртуальных сред, часть работает на Hadoop, YARN или Mesos. Не все инструменты созданы для больших распределенных рабочих нагрузок, когда сбои случаются часто и ожидается восстановление после сбоя.
Экосистема машинного обучения выросла независимо от облачного стека, поэтому часть ее зависит от ноутбуков Jupyter и виртуальных сред, часть работает на Hadoop, YARN или Mesos. Не все инструменты созданы для больших распределенных рабочих нагрузок, когда сбои случаются часто и ожидается восстановление после сбоя.
Методология Broken Roomba и стек Frankenweenie
Поскольку команда K9s прорабатывает детали, важно понимать, что предыдущее обсуждение не отражает того, что происходит на большинстве предприятий. Клыки уже опередили многие компании в том, что знали, что им нужно. Вероятно, у них уже был опыт создания производственных систем машинного обучения.
На самом деле о мониторинге часто забывают, как и о безопасности, особенно когда разработчики платформы или инфраструктуры не участвуют в ранних обсуждениях. Также нередко компании вообще пропускают инфраструктуру и просто начинают с небольшого проекта, который на некоторое время остается незамеченным и естественным образом превращается в монстра Франкенштейна из разнообразных технологий. Придерживаясь собачьей темы, мы называем это стеком Франкенвини: любой набор полуродственных технологий, скрепленных вместе клейкой лентой и молитвами, но в основном последнее.
Придерживаясь собачьей темы, мы называем это стеком Франкенвини: любой набор полуродственных технологий, скрепленных вместе клейкой лентой и молитвами, но в основном последнее.
Хотя MVP может служить надежной основой для будущей платформы машинного обучения, лишь немногие компании делают шаг назад и пересматривают базовую инфраструктуру. Технологии продолжают внедряться из-за недальновидных потребностей, и это может быть опасно для волос, оставшихся на вашей голове, особенно если вы работаете в команде инфраструктуры. Это часто является результатом использования методологии Broken Roomba.
Методология Broken Roomba: метод разработки программного обеспечения, часто используемый неявно, с незнакомыми технологиями, при котором наезд на каждое препятствие ошибочно принимается за прогресс.
Методология Broken Roomba лежит в основе модели, которую передают от специалистов по обработке и анализу данных инженерам по машинному обучению, где разговоры часто ведутся примерно так:
- Она работает на моей машине!
- Почему так долго? Модель была закончена много лет назад.

- Ну, я несколько недель переписывал готовую модель .
Как мы видели ранее, некоторые технологические компании в последние годы успешно создали сквозные платформы машинного обучения. Скорее всего, они также использовали методологию сломанной комнаты, но при наличии достаточных инженерных ресурсов методология сломанной комнаты может напоминать гибкую методологию и привести к успеху.
Легко недооценить сложность создания платформы машинного обучения с нуля, думая, что большинство проблем уже «решено» тем или иным способом, когда на самом деле большая часть технологий все еще находится в стадии разработки. края и построены изолированно от остальной части стека.
Итак, как все это способствует чрезвычайно высокому уровню отказов, упомянутому ранее?
Многие так называемые платформы обработки данных ориентированы на обучение и настройку моделей, то есть на чистую науку о данных. Они оставляют развертывания, где вы действительно видите отдачу от своих инвестиций в машинное обучение, в качестве упражнения для читателя.