Это интересно
- ОКД
- ЗКС
- ИПО
- КНПВ
- Мондиоринг
- Большой ринг
- Французский ринг
- Аджилити
- Фризби
Опрос
Полезные ссылки
РКФ

Все о дрессировке собак

Стрижка собак в Коломне

Поиск по сайту
Управление инцидентами информационной безопасности. Журнал событий информационной безопасности
Мониторинг событий информационной безопасности с помощью ZABBIX / Хабр
 Впервые увидев Zabbix, я подумал, почему бы не попробовать использовать его в качестве решения для мониторинга событий информационной безопасности. Как известно, в ИТ инфраструктуре предприятия множество самых разных систем, генерирующих такой поток событий информационной безопасности, что просмотреть их все просто невозможно. Сейчас в нашей корпоративной системе мониторинга сотни сервисов, которые мы наблюдаем с большой степенью детализации. В данной статье, я рассматриваю особенности использования Zabbix в качестве решения по мониторингу событий ИБ. Что же позволяет Zabbix для решения нашей задачи? Примерно следующее:
Впервые увидев Zabbix, я подумал, почему бы не попробовать использовать его в качестве решения для мониторинга событий информационной безопасности. Как известно, в ИТ инфраструктуре предприятия множество самых разных систем, генерирующих такой поток событий информационной безопасности, что просмотреть их все просто невозможно. Сейчас в нашей корпоративной системе мониторинга сотни сервисов, которые мы наблюдаем с большой степенью детализации. В данной статье, я рассматриваю особенности использования Zabbix в качестве решения по мониторингу событий ИБ. Что же позволяет Zabbix для решения нашей задачи? Примерно следующее:- Максимальная автоматизация процессов инвентаризации ресурсов, управления уязвимостями, контроля соответствия политикам безопасности и изменений.
- Постоянная защита корпоративных ресурсов с помощью автоматического мониторинга информационной безопасности.
- Возможность получать максимально достоверную картину защищенности сети.
- Анализ широкого спектра сложных систем: сетевое оборудование, такое как Cisco, Juniper, платформы Windows, Linux, Unix, СУБД MSQL, Oracle, MySQL и т.д., сетевые приложения и веб-службы.
- Минимизация затрат на аудит и контроль защищенности.
Подготовка
Итак, для начала я установил сервер мониторинга Zabbix. В качестве платформы мы будем использовать ОС FreeBSD. Думаю, что рассказывать в деталях о процессе установки и настройки нет необходимости, довольно подробная документация на русском языке есть на сайте разработчика, начиная от процесса установки до описания всех возможностей системы. Мы будем считать что сервер установлен, настроен, а так же настроен web-frontend для работы с ним. На момент написания статьи система работает под управлением ОС FreeBSD 9.1, Zabbix 2.2.1.Мониторинг событий безопасности MS Windows Server
С помощью системы мониторинга Zabbix можно собирать любую имеющуюся информацию из системных журналов Windows с произвольной степенью детализации. Это означает, что если Windows записывает какое-либо событие в журнал, Zabbix «видит» его, например по Event ID, текстовой, либо бинарной маске. Кроме того, используя Zabbix, мы можем видеть и собирать колоссальное количество интересных для мониторинга безопасности событий, например: запущенные процессы, открытые соединения, загруженные в ядро драйверы, используемые dll, залогиненных через консоль или удалённый доступ пользователей и многое другое.Всё, что остаётся – определить события возникающие при реализации ожидаемых нами угроз.
Устанавливая решение по мониторингу событий ИБ в ИТ инфраструктуре следует учитывать необходимость выбора баланса между желанием отслеживать всё подряд, и возможностями по обработке огромного количества информации по событиям ИБ. Здесь Zabbix открывает большие возможности для выбора. Ключевые модули Zabbix написаны на C/C++, скорость записи из сети и обработки отслеживаемых событий составляет 10 тысяч новых значений в секунду на более менее обычном сервере с правильно настроенной СУБД.
Всё это даёт нам возможность отслеживать наиболее важные события безопасности на наблюдаемом узле сети под управлением ОС Windows.
Итак, для начала рассмотрим таблицу с Event ID, которые, на мой взгляд, очевидно, можно использовать для мониторинга событий ИБ:
События ИБ MS Windows Server Security Log| Описание EventID | 2008 Server | 2003 Server |
| Очистка журнала аудита | 1102 | 517 |
| Вход с учётной записью выполнен успешно | 4624 | 528, 540 |
| Учётной записи не удалось выполнить вход в систему | 4625 | 529-535, 539 |
| Создана учётная запись пользователя | 4720 | 624 |
| Попытка сбросить пароль учётной записи | 4724 | 628 |
| Отключена учётная запись пользователя | 4725 | 629 |
| Удалена учётная запись пользователя | 4726 | 630 |
| Создана защищённая локальная группа безопасности | 4731 | 635 |
| Добавлен участник в защищённую локальную группу | 4732 | 636 |
| Удален участник из защищённой локальной группы | 4733 | 637 |
| Удалена защищённая локальная группа безопасности | 4734 | 638 |
| Изменена защищённая локальная группа безопасности | 4735 | 639 |
| Изменена учётная запись пользователя | 4738 | 642 |
| Заблокирована учётная запись пользователя | 4740 | 644 |
| Имя учётной записи было изменено | 4781 | 685 |

При желании для каждого Event ID можно создать по отдельному элементу данных, но я использую в одном ключе сразу несколько Event ID, чтобы хранить все полученные записи в одном месте, что позволяет быстрее производить поиск необходимой информации, не переключаясь между разными элементами данных.
Хочу заметить что в данном ключе в качестве имени мы используем журнал событий Security. Теперь, когда элемент данных мы получили, следует настроить триггер. Триггер – это механизм Zabbix, позволяющий сигнализировать о том, что наступило какое-либо из отслеживаемых событий. В нашем случае – это событие из журнала сервера или рабочей станции MS Windows.
Теперь все что будет фиксировать журнал аудита с указанными Event ID будет передано на сервер мониторинга. Указание конкретных Event ID полезно тем, что мы получаем только необходимую информацию, и ничего лишнего.
Вот одно из выражений триггера:
{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781].logeventid(4624)}=1&{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781].nodata(5m)}=0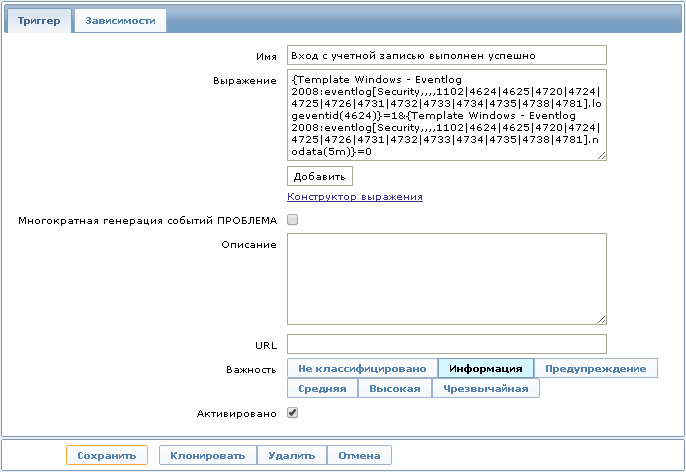
Данное выражение позволит отображать на Dashboard информацию о том что «Вход с учётной записью выполнен успешно», что соответствует Event ID 4624 для MS Windows Server 2008. Событие исчезнет спустя 5 минут, если в течение этого времени не был произведен повторный вход.
Если же необходимо отслеживать определенного пользователя, например “Администратор”, можно добавить к выражению триггера проверку по regexp:
&{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781,,skip].regexp(Администратор)}=1 Тогда триггер сработает только в том случае если будет осуществлён вход в систему именно под учетной записью с именем “Администратор”.P.S. Мы рассматривали простейший пример, но так же можно использовать более сложные конструкции. Например с использованием типов входа в систему, кодов ошибок, регулярных выражений и других параметров.Таким образом тонны сообщений, генерируемых системами Windows будет проверять Zabbix, а не наши глаза. Нам остаётся только смотреть на панель Zabbix Dashboard. Дополнительно, у меня настроена отправка уведомлений на e-mail. Это позволяет оперативно реагировать на события, и не пропустить события произошедшие например в нерабочее время.
Мониторинг событий безопасности Unix систем
Система мониторинга Zabbix так же позволяет собирать информацию из лог-файлов ОС семейства Unix.События ИБ в Unix системах, подходящие для всех Такими проблемами безопасности систем семейства Unix являются всё те же попытки подбора паролей к учётным записям, а так же поиск уязвимостей в средствах аутентификации, например, таких как SSH, FTP и прочих.Некоторые критически важные события в Unix системах Исходя из вышеуказанного следует, что нам необходимо отслеживать действия, связанные с добавлением, изменением и удалением учётных записей пользователей в системе. Так же немаловажным фактом будет отслеживание попыток входа в систему. Изменения ключевых файлов типа sudoers, passwd, etc/rc.conf, содержимое каталогов /usr/local/etc/rc.d наличие запущенных процессов и т.п.Способы мониторинга ИБ в Unix системах Рассмотрим следующий пример. Нужно отслеживать входы в систему, неудачные попытки входа, попытки подбора паролей в системе FreeBSD по протоколу SSH.Вся информация об этом, содержится в лог-файле /var/log/auth.log. По умолчанию права на данный файл — 600, и его можно просматривать только с привилегиями root. Придется немного пожертвовать локальной политикой безопасности, и разрешить читать данный файл группе пользователей zabbix: Меняем права на файл:
chgrp zabbix /var/log/auth.log chmod 640 /var/log/auth.log Нам понадобится новый элемент данных со следующим ключом:log[/var/log/auth.log,sshd,,,skip]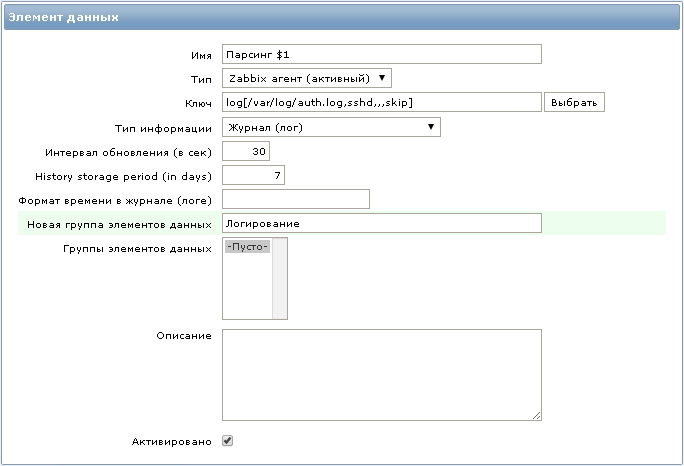
Все строки в файле /var/log/auth.log содержащие слово ”sshd” будут переданы агентом на сервер мониторинга.
Далее можно настроить триггер со следующим выражением:
{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].regexp(error:)}|{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].regexp(Wrong passwordr:)}&{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].nodata(3m)}=0
Это выражение определяется как проблема, когда в лог-файле появляются записи, отобранные по регулярному выражению “error:”. Открыв историю полученных данных, мы увидим ошибки, которые возникали при авторизации по протоколу SSH.
Вот пример последнего значения элемента данных, по которому срабатывает данный триггер:

Рассмотрим ещё один пример мониторинга безопасности в ОС FreeBSD: С помощью агента Zabbix мы можем осуществлять проверку контрольной суммы файла /etc/passwd. Ключ в данном случае будет следующий:
vfs.file.cksum[/etc/passwd] Это позволяет контролировать изменения учётных записей, включая смену пароля, добавление или удаление пользователей. В данном случае мы не узнаем, какая конкретная операция была произведена, но если к серверу кроме Вас доступ никто не имеет, то это повод для быстрого реагирования. Если необходимо более детально вести политику то можно использовать другие ключи, например пользовательские параметры.Например, если мы хотим получать список пользователей, которые на данный момент заведены в системе, можно использовать такой пользовательский параметр:
UserParameter=system.users.list, /bin/cat /etc/passwd | grep -v "#" | awk -F\: '{print $$1}' И, например, настроить триггер на изменение в получаемом списке.Или же можно использовать такой простой параметр:
UserParameter=system.users.online, /usr/bin/users Так мы увидим на Dashboard, кто на данный момент находится в системе:
Мониторинг событий ИБ на сетевых устройствах
С помощью Zabbix можно так же очень эффективно отслеживать события ИБ на сетевых устройствах Cisco и Juniper, используя протокол SNMP. Передача данных с устройств осуществляется с помощью так называемых трапов (SNMP Trap).С точки зрения ИБ можно выделить следующие события, которые необходимо отслеживать — изменения конфигураций оборудования, выполнение команд на коммутаторе/маршрутизаторе, успешную авторизацию, неудачные попытки входа и многое другое.
Способы мониторинга Рассмотрим опять же пример с авторизацией: В качестве стенда я буду использовать эмулятор GNS3 с маршрутизатором Cisco 3745. Думаю многим знакома данная схема.Для начала нам необходимо настроить отправку SNMP трапов с маршрутизатора на сервер мониторинга. В моём случае это будет выглядеть так:
login block-for 30 attempts 3 within 60 login on-failure log login on-success log login delay 5 logging history 5 snmp-server enable traps syslog snmp-server enable traps snmp authentication snmp-server host 192.168.1.1 public Будем отправлять события из Syslog и трапы аутентификации. Замечу, что удачные и неудачные попытки авторизации пишутся именно в Syslog.Далее необходимо настроить прием нужных нам SNMP трапов на сервере мониторинга. Добавляем следующие строки в snmptt.conf:
EVENT clogMessageGenerated .1.3.6.1.4.1.9.9.41.2.0.1 "Status Events" Normal FORMAT ZBXTRAP $ar $N $* SDESC EDESC В нашем примере будем ловить трапы Syslog.Теперь необходимо настроить элемент данных для сбора статистики со следующим ключом:
snmptrap[“Status”]
Если трап не настроен на сервере мониторинга, то в логе сервера будут примерно такие записи:
unmatched trap received from [192.168.1.14]:... В результате в полученном логе будет отражаться информация о попытках входа с детализированной информацией (user, source, localport и reason в случае неудачи):
Ну и можно настроить триггер для отображения события на Dashboard:
{192.168.1.14:snmptrap["Status"].regexp(LOGIN_FAILED)}&{192.168.1.14:snmptrap["Status"].nodata(3m)}=0 В сочетании с предыдущим пунктом у нас на Dashboard будет информация вот такого плана:
Аналогично вышеописанному примеру можно осуществлять мониторинг большого количества событий, происходящих на маршрутизаторах Cisco, для описания которых одной статьей явно не обойтись.
Хочу заметить что приведённый пример не будет работать на продуктах Cisco ASA и PIX, так как там несколько иначе организована работа с логированием авторизации.
Juniper и Syslog Ещё одним примером мы разберем мониторинг авторизации в JunOS 12.1 для устройств Juniper. Тут мы не сможем воспользоваться трапами SNMP, потому как нет поддержки отправки трапов из Syslog сообщений. Нам понадобится Syslog сервер на базе Unix, в нашем случае им будет тот же сервер мониторинга.На маршрутизаторе нам необходимо настроить отправку Syslog на сервер хранения:
system syslog host 192.168.1.1 authorization info Теперь все сообщения об авторизации будут отправляться на Syslog сервер, можно конечно отправлять все сообщения (any any), но переизбыток информации нам не нужен, отправляем только необходимое.Далее переходим к Syslog серверу Смотрим tcpdump, приходят ли сообщения:
tcpdump -n -i em0 host 192.168.1.112 and port 514 12:22:27.437735 IP 192.168.1.112.514 > 192.168.1.1.514: SYSLOG auth.info, length: 106 По умолчанию в настройках syslog.conf все что приходит с auth.info должно записываться в /var/log/auth.log. Далее делаем все аналогично примеру с мониторингом входов в Unix.Вот пример строки из лога:

Остается только настроить триггер на данное событие так же как это было рассмотрено в примере с авторизацией на Unix сервере.
P.S. Таким способом можно отслеживать множество событий, среди которых такие как: сохранение конфигурации устройства (commit), вход и выход из режима редактирования конфигурации (edit). Так же хочу заметить, что аналогичным способом можно осуществлять мониторинг и на устройствах Cisco, но способ с SNMP трапами мне кажется более быстрым и удобным, и исключается необходимость в промежуточном Syslog сервере.Заключение
В заключении хочу отметить, что я с удовольствием приму замечания и дополнения к данной статье, а так же интересные предложения по использованию мониторинга событий информационной безопасности при помощи Zabbix. Спасибо за внимание. :)habr.com
Работа с инцидентами информационной безопасности / Хабр
Доброго дня, уважаемый хабрахабр!Я продолжаю публикацию статей из практики по информационной безопасности. В этот раз речь пойдёт о такой важной составляющей, как инциденты безопасности. Работа с инцидентами займёт львиную долю времени после установления режима информационной безопасности (приняты документы, установлена и настроена техническая часть, проведены первые тренинги).
Информирование об инцидентах
Перво наперво необходимо получить информацию об инциденте. Этот момент необходимо продумать ещё на этапе формирования политики безопасности и создания презентаций по ликбезу в ИБ для сотрудников. Основные источники информации:
1. Helpdesk. Как правило (и это хорошая традиция) о любых неполадках, неисправностях или сбоях в работе оборудования звонят или пишут в хелпдеск вашей IT-службы. Поэтому необходимо заранее «встроиться» в бизнес-процесс хелпдеска и указать те виды инцидентов, с которыми заявку будут переводить в отдел информационной безопасности.
2. Сообщения непосредственно от пользователей. Организуйте единую точку контакта, о чём сообщите в тренинге по ИБ для сотрудников. На данный момент отделы ИБ в организациях, как правило, не очень большие, зачастую из 1-2 человек. Поэтому будет несложно назначить ответственного за приём инцидентов, можно даже не заморачиваться с выделением адреса электропочты под нужды IS Helpdesk.
3. Инциденты, обнаруженные сотрудниками ИБ. Тут всё просто, и никаких телодвижений для организации такого канала приёма не требуется.
4. Журналы и оповещения систем. Настройте оповещения в консоли антивируса, IDS, DLP и других систем безопасности. Удобнее использовать аггрегаторы, собирающие данные также из логов программ и систем, установленных в вашей организации. Особое внимание нужно уделить точкам соприкосновения с внешней сетью и местам хранения чувствительной информации.
Категорирование инцидента
Хоть инциденты безопасности разнообразны и многообразны, их довольно легко разделить на несколько категорий, по которым проще вести статистику.
1. Разглашение конфиденциальной или внутренней информации, либо угроза такого разглашения. Для этого необходимо иметь, как минимум, актуальный перечень конфиденциальной информации, рабочую систему грифования электронных и бумажных носителей. Хороший пример — шаблоны документов, практически на все случаи жизни, находящиеся на внутреннем портале организации или во внутренней файлопомойке, по умолчанию имеют проставленный гриф «Только для внутреннего использования». Немного уточню про угрозу разглашения, в предыдущем посте я описывал ситуацию, когда документ с грифом «Только для внутреннего использования» был вывешен в общем холле, смежным с другой организацией. Возможно, самого разглашения и не было (вывешено было после окончания рабочего дня, да и замечено было очень быстро), но факт угрозы разглашения — на лицо!
2. Несанкционированный доступ. Для этого необходимо иметь список защищаемых ресурсов. То есть тех, где находится какая-либо чувствительная информация организации, её клиентов или подрядчиков. Причём желательно внести в эту категорию не только проникновения в компьютерную сеть, но и несанкционированный доступ в помещения.
3. Превышение полномочий. В принципе можно объединить этот пункт с предыдущим, но лучше всё-таки выделить, объясню почему. Несанкционированный доступ подразумевает доступ тех лиц, которые не имеют никакого легального доступа к ресурсам или помещениям организации. Это внешний нарушитель, не имеющий легального входа в вашу систему. Под превышением полномочий же понимается несанкционированный доступ к каким-либо ресурсам и помещениям именно легальных сотрудников организации.
4. Вирусная атака. В этом случае необходимо понимать следующее: единично заражение компьютера сотрудника не должно повлечь за собой разбирательство, так как это можно списать на погрешность или пресловутый человеческий фактор. Если же заражен ощутимый процент компьютеров организации (тут уже исходите из общего количества машин, их распределенности, сегментированности и тд), то необходимо разворачивать полновесную отработку инцидента безопасности с необходимыми поисками источников заражения, причин и т.д.
5. Компрометация учетных записей. Этот пункт перекликается с 3. Фактически инцидент переходит из 3 в 5 категорию, если в ходе расследования инцидента выясняется, что пользователь в этот момент физически и фактически не мог использовать свои учётные данные.
Классификация инцидента
С этим пунктом в работе с инцидентами можно поступить 2-мя путями: простым и сложным. Простой путь: взять соглашение об уровне сервиса вашей IT-службы и подогнать под свои нужды. Сложный путь: на основе анализа рисков выделить группы инцидентов и/или активов, в отношении которых решение или устранение причин инцидента должны быть незамедлительными. Простой путь неплохо работает в небольших организациях, где не так уж и много закрытой информации и нет огромного количества сотрудников. Но стоит понимать, что IT-служба исходит в SLA из своих собственных рисков и статистики инцидентов. Вполне возможно, что зажевавший бумагу принтер на столе генерального директора будет иметь очень высокий приоритет, в том случае, как для вас важнее будет компрометация пароля администратора корпоративной БД.
Сбор свидетельств инцидента
Есть особенная прикладная наука — форензика, которая занимается вопросам криминалистики в области компьютерных преступлений. И есть замечательная книга Федотова Н.Н. «Форензика — компьютерная криминалистика». Я не буду сейчас расписывать детально аспекты форензики, просто выделю 2 основных момента в сохранении и предоставлении свидетельств, которых необходимо придерживаться.
• Для бумажных документов: подлинник хранится надежно с записью лица, обнаружившего документ, где документ был обнаружен, когда документ был обнаружен и кто засвидетельствовал обнаружение. Любое расследование должно гарантировать, что подлинники не были сфальсифицированы • Для информации на компьютерном носителе: зеркальные отображение или любого сменного носителя, информации на жестких дисках или в памяти должны быть взяты для обеспечения доступности. Должен сохраняться протокол всех действий в ходе процесса копирования, и процесс должен быть засвидетельствован. Оригинальный носитель и протокол (если это невозможно, то, по крайней мере, одно зеркальное отображение или копия), должны храниться защищенными и нетронутыми
После устранения инцидента
Итак, инцидент исчерпан, последствия устранены, проведено служебное расследование. Но работа на этом не должна завершаться. Дальнейшие действия после инцидента:
• переоценка рисков, повлекших возникновение инцидента • подготовка перечня защитных мер для минимизации выявленных рисков, в случае повторения инцидента • актуализация необходимых политик, регламентов, правил ИБ • провести обучение персонала организации, включая сотрудников IT, для повышения осведомленности в части ИБ
То есть необходимо предпринять все возможные действия по минимизации или нейтрализации уязвимости, повлекшей реализацию угрозы безопасности и, как результат, возникновение инцидента.
Несколько советов
1. Ведите журнал регистрации инцидентов, где записывайте время обнаружения, данные сотрудника, обнаружившего инцидент, категорию инцидента, затронутые активы, планируемое и фактическое время решения инцидента, а так же работы, проведенные для устранения инцидента и его последствий.2. Записывайте свои действия. Это необходимо в первую очередь для себя, для оптимизации процесса решения инцидента.3. Оповестите сотрудников о наличие инцидента, что бы во-первых они не мешали вам в расследовании, во-вторых исключили пользование затронутыми активами на время расследования.
habr.com
Управление инцидентами информационной безопасности | Управление инцидентами ИБ
Система защиты от утечек информации основывается в том числе на выявлении, предотвращении, регистрации и устранении последствий инцидентов информационной безопасности или событий, нарушающих регламентированные процедуры защиты ИБ. Существует ряд методик, определяющих основные параметры управления ими. Эти методики внедряются на уровне международных стандартов, устанавливающих критерии оценки качества менеджмента в компании. События или инциденты ИБ в рамках этих регламентов выявляются и регистрируются, их последствия устраняются, а на основании анализа причин их возникновения положения и методики дорабатываются.
Понятие инцидента
Международные регламенты, действующие в сфере сертификации менеджмента информационных систем, дают свое определение этому явлению. Согласно им инцидентом информационной безопасности является единичное событие нежелательного и непредсказуемого характера, которое способно повлиять на бизнес-процессы компании, скомпрометировать их или нарушить степень защиты информационной безопасности. На практике к этому понятию относятся разноплановые события, происходящие в процессе работы с информацией, существующей в электронной форме или на материальных носителях. К ним может относиться и оставление документов на рабочем столе в свободном доступе для другого персонала, и хакерская атака – оба инцидента в равной мере могут нанести ущерб интересам компании.
Среди основных типов событий присутствуют:
- нарушение порядка взаимодействия с Интернет-провайдерами, хостингами, почтовыми сервисами, облачными сервисами и другими поставщиками телекоммуникационных услуг;
- отказ оборудования по любым причинам, как технического, так и программного характера;
- нарушение работы программного обеспечения;
- нарушение любых правил обработки, хранения, передачи информации, как электронной, так и документов;
- неавторизированный или несанкционированный доступ третьих лиц к информационным ресурсам;
- выявление внешнего мониторинга ресурсов;
- выявление вирусов или других вредоносных программ;
- любая компрометация системы, например, попадание пароля от учетной записи в открытый доступ.
Все эти события должны быть классифицированы, описаны и внесены во внутренние документы компании, регламентирующие порядок обеспечения информационной безопасности. Кроме того, в регламентирующих документах необходимо установить иерархию событий, разделить их на более или менее значимые. Следует учитывать, что существенная часть инцидентов малозаметны, они происходят вне периметра внимания должностных лиц. Такие события должны быть описаны особо, и определены меры для их выявления в режиме постфактум.
При описании мер реакции следует учитывать, что изменение частоты появления и общего количества инцидентов информационной безопасности является одним из показателей качества работы систем, обеспечивающих ИБ, и само по себе классифицируется в качестве существенного события. Учащение событий может говорить о намеренной атаке на информационные системы компании, поэтому оно должно стать основанием для анализа и дальнейшего повышения уровня защиты.
Место управления инцидентами в общей системе информационной безопасности
Регламенты, определяющие порядок управления инцидентами информационной безопасности, должны стать составной частью бизнес-процессов и их регламентации. Предполагая, что инцидентом является недозволенное, несанкционированное событие, в работе нужно опираться на механизм, разделяющий события и действия на разрешенные и запрещенные, определяющий органы, имеющие права на разработку таких норм. Кроме того, регламент определяет методы и способы классификаций событий, прямо не обозначенных в документах в качестве значимых, и механизм выявления таких событий, их описания и последующего внесения в регламентирующие документы.
Например, в регламенте может быть запрещено размещение конфиденциальной информации на портативных носителях без ее кодировки или шифрования, при этом не будет прямо установлен запрет на вынос таких устройств за пределы компании. Случайная утрата компьютера в результате криминального посягательства станет инцидентом, но он не будет прямо запрещен. Соответственно, в документах должен быть установлен механизм дополнения норм и правил безопасности в ситуативном порядке без излишней бюрократии. Это позволит оперативно реагировать на новые вызовы и дорабатывать меры защиты своевременно, а не со значительным запозданием.
Система сертификации ISO 27001 в качестве одного из элементов ИБ предполагает необходимость создания отдельной процедуры управления инцидентами информационной безопасности в рамках общей системы стандартизации бизнес-процессов.
Особенности управления событиями безопасности
Несмотря на то, что стандарты прямо рекомендуют внедрять методики управления инцидентами информационной безопасности, на практике внедрение и реализация этих практик встречают множество сложностей. Отдельные процедуры управления инцидентами не внедряются. Этот показатель не говорит о том, что системы менеджмента инцидентов работают хорошо или плохо, это свидетельствует только о том, что существует определенная брешь в системе безопасности.
Управление инцидентами информационной безопасности основано на следующих действиях:
- определение. В организации отсутствует методика выявления и классификации инцидентов, описание их основных параметров, поэтому сотрудники встают перед необходимостью или самостоятельно определять критерии события, или игнорировать его. Вход в сеть под аккаунтом другого сотрудника, согласно стандартам, является инцидентом информационной безопасности, но он не будет зафиксирован в журнале, так как сотрудники считают такое поведение стандартным и дозволенным, особенно в условиях дефицита кадровых ресурсов;
- оповещение о возникновении. Даже если какое-либо событие может быть определено согласно принятым в организации методикам или личному мнению сотрудника как инцидент, чаще всего в организации не разработаны стандарты и маршруты оповещения о таких событиях. Даже если кем-то будет выявлен факт копирования документов, относящихся к коммерческой тайне, сотрудник встанет в тупик перед вопросом, кто именно и в какой форме должен быть оповещен об этом инциденте: его руководитель, служба безопасности или иное лицо;
- регистрация. Эта часть стандартов является наиболее невыполнимой для российских компаний, инциденты не идентифицируются, соответственно, не фиксируются. Отсутствует практика заведения регистров учета, в которых бы фиксировались значимые события, что впоследствии давало бы материал для их анализа и прогноза возможных атак;
- устранение причин и последствий. Любой инцидент вызывает определенные следы и последствия, которые, с одной стороны, могут мешать деятельности компании, с другой – служат материалом для проведения расследования причин его возникновения. Отсутствие регламентов устранения последствий может привести как к накоплению ошибок, так и к полному уничтожению доказательственной базы, позволяющей выявить виновника произошедшей ситуации. Любые срочные меры, предпринимаемые для восстановления стабильности, могут случайно или намеренно уничтожить следы проникновения в базу данных;
- меры реагирования на инциденты. В ряде случаев возникновение инцидента может потребовать срочных мер реагирования, например, отключения компьютера от сети, приостановки передачи информации, установки контакта с провайдером. Должны быть определены органы и должностные лица, ответственные за разработку механизма реагирования и его оперативную реализацию;
- расследование. Полномочия по расследованию должны быть переданы из ведения IT-службы в компетенцию служб безопасности. В рамках расследования должны быть изучены журналы учета, проанализированы действия всех пользователей и администраторов, которые имели доступ к системам в период возникновения чрезвычайной ситуации. Расследование должно стать одним из основных элементов управления инцидентами. На практике в российских компаниях от реализации этого этапа отказываются, ограничиваясь устранениями последствий произошедшего события. При необходимости расследование должно производиться с привлечением оперативно-следственных органов;
- реализация превентивных мер. В большинстве случаев инциденты не являются единичными, их возникновение свидетельствует о том, что в системе ИБ возникла брешь и аналогичные случаи будут повторяться. Во избежание этих рисков необходимо по результатам расследования подготовить протокол или акт комиссии, в котором определить, какие именно меры должны быть применены для предотвращения аналогичных ситуаций. Кроме того, применяются определенные меры дисциплинарной ответственности, предусмотренные Трудовым кодексом и внутренними регламентами;
- аналитика. Все события, нарушающие регламентированные процессы и могущие быть квалифицированы в качестве инцидентов информационной безопасности, должны стать основой для анализа, который поможет определить их характер, проявить системность и выработать рекомендации для совершенствования системы ИБ, действующей в компании.
Основные проблемы, связанные с нарушением процедур, обусловлены неготовностью персонала в полной мере воспринимать, адаптировать и выполнять рекомендации. Касательно инцидентов информационной безопасности, сложности в восприятии и реакции вызывают моменты, связанные с совершением действий, которые прямо не регламентированы инструкциями или стандартами или вызывают ощущение излишних или избыточных.
Процедура управления
Как любая корпоративная процедура, организация управления инцидентами информационной безопасности должна пройти несколько этапов: от принятия решения о его необходимости до внедрения и аудита. На практике менеджмент большинства предприятий не осознает необходимости применения этой практики защиты информационного периметра, поэтому для возникновения инициативы о ее внедрении часто требуется аудит систем ИБ внешними консультантами, выработка ими рекомендаций, которые затем будут реализованы руководством предприятия. Таким образом, начальной точкой для реализации процедур управления инцидентами ИБ становится решение исполнительных органов или иногда более высоких звеньев системы управления компании, например, Совета директоров.
Общее решение обычно принимается в русле модернизации существующей системы ИБ. Система управления инцидентами является ее основной частью. На уровне принятия решения необходима его локализация в общей парадигме целей компании. Оптимально, если функционирование системы ИБ становится одной из бизнес-целей организации, а качество ее работы подкрепляется установлением ключевых показателей эффективности для ответственных сотрудников компании. После определения статуса функционирования системы необходимо перейти к разработке внутренней документации, опосредующей связанные с ней отношения в компании.
Для придания значимости методикам управления информационной безопасностью они должны быть утверждены на уровне исполнительного органа (генерального директора, правления или совета директоров). С данными документа необходимо ознакомить всех сотрудников, имеющих отношение к работе с информацией, существующей в электронных формах или на материальных носителях.
В структуре документа, оформляемого в виде положения или регламента, должны выделяться следующие подразделы:
- определение событий, признаваемых инцидентами применительно к системе безопасности конкретной компании. Так, пользование внешней электронной почтой может быть нарушением ИБ для государственной компании и рядовым событием для частной;
- порядок оповещения о событии. Должны быть определены формат уведомления (устный, докладная записка, электронное сообщение), перечень лиц, которые должны быть оповещены, и дублирующие их должности в случае их отсутствия, перечень лиц, до которых также доносится информация о событии (руководство компании), срок уведомления после получения информации об инциденте;
- перечень мероприятий по устранению последствий инцидента и порядок их реализации;
- порядок расследования, в котором определяются ответственные за него должностные лица, механизм сбора и фиксации доказательств, возможные действия по выявлению виновника;
- порядок привлечения виновных лиц к дисциплинарной ответственности;
- меры усиления безопасности, которые должны быть применены по итогам расследования инцидента;
- порядок минимизации вреда и устранения последствий инцидентов.
При разработке регламентов, опосредующих систему управления событиями ИБ, желательно опираться на уже созданные и показавшие свою эффективность методики и документы, включая формы отчетов, журналы регистрации, уведомления о событии.
Устранение причин и последствий события, его расследование
Непосредственно после уведомления соответствующих должностных лиц о произошедшем инциденте и его фиксации необходимо совершить действия реагирования, а именно устранения причин и последствий события. Все этапы этих процессов должны найти свое отражение в регламентах. Там описываются перечни общих действий для отдельных наиболее значимых событий, конкретные шаги и сроки применения мер. Необходимо также предусмотреть ответственность за неприменение установленных мер или недостаточно эффективное их применение.
На этапе расследования от должностных лиц организации требуется:
- определить причины возникновения инцидента и недостатки регламентирующих документов и методик, сделавших возможным его возникновение;
- установить ответственных и виновных лиц;
- собрать и зафиксировать доказательства;
- установить мотивы совершения инцидента и круг лиц, причастных к нему помимо персонала компании, выявить заказчика.
Если предполагается в дальнейшем возбуждение судебного преследования по факту инцидента на основании совершения преступления в сфере информационной безопасности или нарушения режима коммерческой тайны, к расследованию уже на начальном этапе необходимо привлечь оперативно-следственные органы. Собранные самостоятельно факты без соблюдения процессуальных мер не будут признаны надлежащими доказательствами и приобщены к делу.
Превентивные меры, изменения стандартов и ликвидация последствий
Непосредственно после выявления инцидента предпринимаются оперативные меры по устранению его последствий. На следующем этапе необходим анализ причин его возникновения и совершение комплекса действий, направленных на предотвращение возможного повторения аналогичного события. Сегодня основным регламентирующим документом, предлагающим стандарты реакции на инциденты, стал ISO/IEC 27000:2016, это последняя версия совместной разработки ISO и Энергетической комиссии. В России на основе более ранних версий ISO/IEC разработаны ГОСТы. В рамках ISO/IEC 27000:2016 предлагается создать специальную службу поддержки, Service Desk, на которую должны быть возложены функции управления инцидентами.
Аудит соблюдения стандартов
При получении сертификата соответствия по стандарту ISO 27001, а также при проверке соблюдений требований стандарта проводится аудит выполнения методик управления инцидентами информационной безопасности. При проведении аудита часто выясняется, что даже при внедрении стандартов возникает существенное количество проблем и недопониманий, связанных с регистрацией инцидентов и расследованием событий, послуживших причиной для их возникновения. Расследования осложняются тем, что под одной учетной записью могут входить несколько операторов или администраторов, что затрудняет их аутентификацию. На контроллере серверов в большинстве случаев не заводятся и не ведутся журналы учета событий. Отсутствие контролируемой системы идентификации пользователей, характерное для большинства российских компаний, позволяет в произвольном режиме менять информацию, останавливать серверы или модифицировать их работу. ИБ, внедренные в большинстве российских компаний, не позволяют контролировать действия администраторов.
Рекомендуется проведение аудита не реже чем раз в полгода. Его результатами должны стать обновление перечня событий, признаваемых инцидентами, доработка перечня необходимых действий по их устранению, изменение программных средств, обеспечивающих защиту информационного периметра. Если в компании установлены DLP-системы и SIEM-системы, то с учетом проведенного анализа инцидентов, произошедших за определенный период, и результатов аудита они могут быть доработаны.
Аудит не должен быть единственным фактором, выявляющим недостатки работы системы. Еще на этапе ее внедрения должны быть разработаны системы контроля качества процессов, результаты работы которых должны обрабатываться в регулярном режиме.

ИБ-ИНСТРУМЕНТЫ ДЛЯ БИЗНЕСА
Выберите нужно решение: DLP, SIEM или систему контроля рабочего времени – и получите бесплатно версию для тестирования.
searchinform.ru
Практика ИБ \ Аудит событий безопасности
Антон Чувакин выложил в своем блоге интересную "шпаргалку", в которой приведены все наиболее важные виды событий, которые нужно собирать и анализировать в рамках текущей деятельности и при разборе инцидентов безопасности. Может очень пригодиться на начальном этапе внедрения практического аудита событий, когда нужно из огромной массы возможных событий выбрать тот разумный минимум, который позволит накапливать всю нужную информацию и при этом не утонуть в море "шума". Особенно актуально при анализе событий полуручными методами.Основной подход- Определите, какие источники журналов и какие автоматизированные средства вы можете использовать в процессе анализа
- Организуйте копирование всех записей журналов в одно место, где вы сможете их анализировать
- Минимизируйте "шум", исключив из анализа обычные, повторяющиеся записи (предварительно убедившись, что они не представляют угрозы)
- Убедитесь, что вы можете положиться на отметки о времени событий в журналах, примите во внимание возможные различия во временных зонах
- Сосредоточьтесь на необычных для вашей среды событиях - последних изменениях, ошибках, изменениях состояния, событиях доступа, выполнении административных функций и т.п.
- Возвращайтесь назад во времени для реконструкции действий до и после произошедшего инцидента
- Совмещайте (коррелируйте) действия, зафиксированные в различных журналах, для получения полной картины произошедшего
- Создайте для себя предположение о произошедшем, а затем исследуйте журналы, чтобы подтвердить или опровергнуть это предположение
- Журналы регистрации событий операционных систем серверов и рабочих станций
- Журналы регистрации событий приложений (например, веб-серверов, серверов баз данных)
- Журналы регистрации событий средств безопасности (например, антивирусных программ, средств контроля изменений, систем выявления/предотвращения вторжений)
- Журналы регистрации событий внешнего прокси-сервера
- Журналы регистрации событий приложений конечного пользователя
- Не забудьте принять во внимание иные (не журнальные) источники событий безопасности
- ОС Linux и основные приложения: /var/logs
- ОС Windows и основные приложения: Журнал регистрации событий Windows (Безопасность, Система, Приложение)
- Сетевые устройства: обычно журналируются посредством Syslog; некоторые используют собственные местоположения и форматы
- Успешный вход пользователя
- “Accepted password” (пароль принят)
- “Accepted publickey” (открытый ключ принят)
- "session opened” (открыт сеанс)
- Неудачный вход пользователя
- “authentication failure” (неудачная аутентификация)
- “failed password” (неверный пароль)
- Выход пользователя
- “session closed” (сеанс закрыт)
- Изменение или удаление пользовательской учетной записи
- “password changed” (изменен пароль)
- “new user” (создан новый пользователь)
- “delete user” (удален пользователь)
- Использование sudo
- “sudo: … COMMAND=…”(использование sudo)
- “FAILED su” (неудачная попытка использования su)
- Сбои сервисов
- “failed” или “failure”
- Указанные ниже идентификаторы событий соответствуют Windows 2000/XP/2003. Для Vista/7 нужно добавлять к приведенному здесь номеру 4096 для получения правильного идентификатора события
- Большинство приведенных ниже событий записывается в журнал "Безопасность"; многие из событий журналируются только на контроллере домена
- События входа/выхода пользователей
- Успешный вход - 528, 540; неудачный вход - 529-537, 539; выход - 538, 551 и т.д.
- Изменения пользовательских учетных записей
- Создание - 624; разблокирование - 626; изменение - 642; блокирование - 629; удаление - 630
- Изменения пароля
- Для своей учетной записи - 628; для другой учетной записи - 627
- Запуск и остановка сервисов
- Отказ в доступе к объекту (если включен соответствующий аудит)
- Контролировать следует как внутреннюю, так и внешнюю активность
- Приведенные ниже примеры относятся к журналам Cisco ASA, однако для других устройств все аналогично
- Разрешенный на межсетевом экраноме трафик
- “Built … connection” (установлено соединение)
- “access-list … permitted” (разрешен сетевой пакет в соответствии с ACL при включенной для правила опции LOG)
- Заблокированный на межсетевом экране трафик
- “access-list … denied” (блокирован сетевой пакет в соответствии с ACL при включенной для правила опции LOG)
- “deny inbound” (блокировано входящее соединение)
- “Deny … by” (блокирован сетевой пакет в соответствии с ACL; журналируется даже при выключенной опции LOG)
- Объемы переданных данных (для выявления передачи больших объемов данных)
- “Teardown TCP connection … duration … bytes …” (завершено ТСР-соединение, длительность, передано байт)
- Использование полосы пропускания и ресурсов
- “limit … exceeded” (превышен лимит)
- “CPU utilization” (использование процессора)
- Выявленные атаки
- “attack from” (атака от)
- Изменения пользовательских учетных записей
- “user added” (пользователь добавлен)
- “user deleted” (пользователь удален)
- “User priv level changed” (изменены привилегии пользователя)
- Административный доступ
- “AAA user …” (доступ пользователя)
- “User … locked out” (пользователь заблокирован)
- “login failed” (неудачная попытка входа)
- Большое число попыток доступа к несуществующим файлам
- Что-то похожее на код (SQL, HTML) в URL-запросах
- Попытки доступа к отсутствующим у вас расширениям
- Сообщения об остановке/запуске/сбое веб-сервиса
- Доступ к рискованным страницам, которые принимают пользовательский ввод
- Просмотр журналов регистрации событий на всех серверах пула
- Код ошибки 200 на отсутствующих у вас файлах
- Неудачная аутентификация пользователя
- Коды ошибки 401, 403
- Неверный запрос
- Внутренняя ошибка сервера
dorlov.blogspot.com
Практика ИБ \ Процедуры анализа журналов регистрации событий в соответствии с PCI DSS. Часть 1
Антон Чувакин опубликовал в своем блоге практическое Руководство по организации процедур анализа журналов регистрации событий в соответствии с требованиями PCI DSS. Руководство достаточно универсально и может использоваться в качестве основы при организации анализа событий в рамках любых других требований, в том числе СТО БР ИББС-1.0, РС БР ИББС-2.3, ISO 27002, CobiT, либо просто в рамках реализации программы обеспечения безопасности компании без каких-либо внешних требований.При переводе руководство было мной немного актуализировано и приведено в соответствие с требованиями новой версии PCI DSS 2.0. Руководство состоит из трех основных частей:
- Описание требований PCI DSS в части журналирования событий,
- Описание процедур анализа журналов регистрации событий,
- Описание доказательств, которые потребуются для подтверждения соответствия требованиям PCI DSS в части журналирования событий.
В первой части рассмотрены следующие вопросы:
- Цели создания Руководства
- Начальные требования и предположения
- Вопросы, которые не вошли в Руководство
- Роли и обязанности
- Требования PCI DSS в части журналирования событий
- Требования раздела 10 PCI DSS
- Другие требования, связанные с журналами регистрации событий
Несколько советов тем, кто решит воспользоваться этим Руководством в своей компании:
- Если вам нужно организовать процедуры анализа журналов регистрации событий в соответствии с требованиями п.10.6 PCI DSS («анализируйте журналы регистрации событий всех системных компонентов не реже одного раза в день») – пользуйтесь этим Руководством и адаптируйте его для своей среды.
- В Руководстве больше внимания уделяется журналированию событий операционной системы и приложений, но вам потребуется также анализировать события сетевых устройств и средств безопасности. К ним применимы те же методы и подходы.
- Руководство было проанализировано QSA и было им одобрено. Однако мнение вашего QSA может быть иным.
- Должна быть разработана Политика ведения журналов регистрации событий и другие нормативные документы, детализирующие и систематизирующие требования PCI DSS в отношении журналирования событий.
- Ведение журналов регистрации событий должно быть включено на всех системах, входящих в область, к которой применяются требования PCI DSS.
- Факты отключения или прерывания процесса журналирования событий должны регистрироваться и отслеживаться.
- В журналы регистрации событий должны записываться все события, требуемые PCI DSS и Политикой ведения журналов регистрации событий.
- Создаваемые журналы регистрации событий должны соответствовать требованиям PCI DSS (в частности, требованиям п.10.3).
- Время на всех системах, входящих в область действия PCI DSS, должно быть синхронизировано с использованием надежного сервера времени (с помощью NTP или другой технологии, соответствующей требованиям п.10.4 PCI DSS).
- Часовые пояса, в которых работают системы, выполняющие журналирование событий, должны быть известны, зафиксированы и пригодны для учета в процессе анализа журналов.
- Человек, чьи действия журналируются на определенной системе, не может быть единственным, кто выполняет анализ журналов регистрации событий этой же системы.
- Все попытки получения доступа к журналам регистрации событий должны регистрироваться и отслеживаться для выявления попыток отключения журналирования событий или иных попыток воздействия на ведение и содержимое журналов.
| Вопрос | Почему он не вошел в Руководство? |
| Какие события должны журналироваться в каждом приложении? | Настоящее Руководство касается только процедур анализа журналов регистрации событий. Предполагается, что само журналирование уже реализовано надлежащим образом в соответствии с требованиями PCI DSS и Политики ведения журналов регистрации событий |
| Какую информацию нужно записывать в журнал для каждого журналируемого события в каждом приложении? | Настоящее Руководство касается только процедур анализа журналов регистрации событий. Предполагается, что само журналирование уже реализовано надлежащим образом в соответствии с требованиями PCI DSS и Политики ведения журналов регистрации событий |
| Высокоуровневая политика ведения и мониторинга журналов регистрации событий | Подразумевается, что эта политика уже должна быть введена в действие |
| Политики и процедуры сбора, обработки и сохранения событий | Эти процедуры не рассматриваются в настоящем Руководстве |
| Процедуры реагирования на инциденты информационной безопасности | Настоящее Руководство касается только процедур анализа журналов регистрации событий. Выполнение этих процедур иногда приводит к необходимости инициирования процедур реагирования на инциденты и проведения расследований |
| Приложения, которые не входят в область действия PCI DSS | Настоящее Руководство охватывает только приложения, находящиеся в области действия PCI DSS |
| Сетевые устройства, которые входят или не входят в область действия PCI DSS | Настоящее Руководство охватывает только приложения, находящиеся в области действия PCI DSS. Но в вашем проекте по организации анализа журналов регистрации событий сетевые устройства обязательно должны быть учтены! |
| Контроль доступа к хранящимся журналам регистрации событий, защита конфиденциальности и целостности данных в журналах регистрации событий | Эти процедуры не рассматриваются в настоящем Руководстве |
| Компенсирующие меры для случаев, когда ведение журналов регистрации событий невозможно | Настоящее Руководство касается только процедур анализа журналов регистрации событий. Анализ журналов всегда возможен, если возможно их ведение. Ситуации, когда ведение журналов невозможно, в настоящем Руководстве не рассматриваются |
| Мониторинг в режиме реального времени состояния централизованной системы журналирования событий, ее производительности и т.п. | Настоящее Руководство касается только процедур анализа журналов регистрации событий |
| Требования к журналированию событий, помимо разделов 10 и 12 PCI DSS | Настоящее Руководство ограничивается только требованиями разделов 10 и 12 PCI DSS. Краткий обзор других требований к журналированию также приводится, но для них не приводятся детальные процедуры |
| Гарантии успешного прохождения аудита на соответствие требованиям PCI DSS | Только QSA каждой компании может предоставить такие гарантии после проведения аудита |
| Правила корреляции для мониторинга событий | Настоящее Руководство касается только процедур анализа журналов регистрации событий, но не правил корреляции. Однако некоторые вопросы, имеющие отношение к правилам корреляции, в настоящем Руководстве рассматриваются |
| Сохранение записей журнала регистрации событий для целей криминалистического анализа | Вопрос сохранения записей журнала регистрации событий для целей криминалистического анализа, относится к процедурам реагирования на инциденты |
| Роль | Обязанности | Пример участия в анализе журналов |
| Администратор приложения | Администрирует приложение | Настройка системы регистрации событий в приложении, выполнение ежедневного анализа журналов регистрации событий для выявления технических проблем |
| Системный и сетевой администратор | Администрирует операционную систему, на которой работает приложение, и сеть | Настройка системы регистрации событий, выполнение ежедневного анализа журналов регистрации событий для выявления технических проблем |
| Бизнес-владелец приложения | Руководитель бизнес-подразделения, ответственный за приложение | Утверждает изменения в конфигурации приложения в части ведения и анализа журналов регистрации событий |
| Администратор безопасности | Администрирует средства безопасности на одной или нескольких системах / приложениях | Настройка механизмов безопасности и системы аудита в приложении, выполнение ежедневного анализа журналов регистрации событий для выявления технических проблем (только принимает участие!) |
| Аналитик безопасности | Работает с процессами обеспечения безопасности при эксплуатации приложения | Использование систем безопасности, просмотр журналов регистрации событий и других данных, выполнение ежедневного анализа журналов регистрации событий |
| Руководитель подразделения информационной безопасности | Контролирует соблюдение политики безопасности, выполнение процессов обеспечения безопасности, эксплуатации средств безопасности | Владелец процедур анализа журналов регистрации событий, обновляет эти процедуры по мере необходимости |
| Ответственный за реагирование на инциденты | Участвует в мероприятиях по реагированию на инциденты безопасности | Работа с инцидентами безопасности, анализ журналов регистрации событий в рамках мероприятий по реагированию на инциденты безопасности |
10.1
«Реализуйте процесс, обеспечивающий связь любых фактов доступа к системным компонентам (в особенности доступа, с использованием административных привилегий, например, root) с конкретными пользователями». PCI DSS не просто требует обеспечить наличие журналов регистрации событий или организовать процесс их сбора, он требует обеспечить связь событий, отраженных в журнале регистрации, с конкретными людьми (а не компьютерами или устройствами, которые были источником события). Это требование часто создает проблемы для внедряющих PCI DSS. Многие начинают думать о журналах, как о «записях о действиях людей», тогда как в действительности они являются «записями о действиях компьютеров». Кстати, требование п.8.1 PCI DSS, которое говорит, что «каждому пользователю должно быть присвоено уникальное имя (идентификатор) до предоставления ему доступа к системным компонентам или данным платежных карт», помогает и при реализации требования п.10.1, делая журналы регистрации событий более полезными.10.2
п.10.2 определяет минимальный перечень системных событий, которые должны журналироваться. Это требование вызвано необходимостью проведения оценки и мониторинга действий пользователей, а также других событий, которые могут оказать влияние на данные платежных карт (например, системные сбои). Ниже представлен список событий, которые должны журналироваться в соответствии с этим пунктом:- «10.2.1. Любой доступ к данным платежных карт
- 10.2.2. Все действия, выполненные с использование административных привилегий
- 10.2.3. Доступ к любым журналам регистрации событий
- 10.2.4. Неудачные попытки логического доступа
- 10.2.5. Использование механизмов идентификации и аутентификации
- 10.2.6. Инициализация журналов регистрации событий
- 10.2.7. Создание и удаление системных объектов»
10.3
Далее раздел 10 PCI DSS опускается до еще более детального уровня и указывает конкретные данные, которые должны записываться в журнал регистрации событий для каждого события. Это вполне разумные минимальные требования, которые обычно не превышают стандартных возможностей механизмов регистрации событий большинства ИТ-платформ. Записи подлежат следующие данные:- «10.3.1. Идентификатор пользователя
- 10.3.2. Тип события
- 10.3.3. Дата и время события
- 10.3.4. Индикатор успеха или отказа
- 10.3.5. Источник события
- 10.3.6. Идентификатор или название задействованных данных, системного компонента или ресурса»
10.4
Следующий пункт требований учитывает очень важный аспект, про который часто забывают: необходимость использования при журналировании событий точного и согласованного времени. Очевидно, что время событий, которое будет записываться в журнал регистрации событий, будет браться на основе системного времени компьютера. Однако время на различных системах может различаться или вообще быть настроено некорректно. Это может сильно затруднить корреляцию и анализ событий с нескольких различных систем. Поэтому требуется настроить синхронизацию времени на всех критичных системах на основе надежного источника, например, службы NTP.Во второй версии PCI DSS это требование немного детализировано, в него добавлены следующие подпункты:
- «10.4.1. На критичных системах должно быть установлено правильное и согласованное время
- 10.4.2. Данные времени должны быть защищены
- 10.4.3. Должно быть настроено получение текущего времени из надежных источников».
10.5
Далее, нужно учесть вопросы обеспечения конфиденциальности, целостности и доступности журналов регистрации событий. Пункт 10.5.1 PCI DSS касается конфиденциальности: «просмотр журналов регистрации событий должен быть разрешен только тем сотрудникам, которым это необходимо для выполнения своих должностных обязанностей». Причиной такого ограничения является высокая вероятность наличия в журналах регистрации событий конфиденциальной информации. Например, неудачные попытки аутентификации записываются в журнал с указанием использованного имени пользователя, при этом пользователь может ошибиться и ввести в поле имени свой пароль. Другим примером может быть плохо написанное приложение, которое может указывать пароль пользователя в адресах URL, которые сохраняются в журнале регистрации событий веб-сервера.Следующим вопросом является целостность. Пункт 10.5.2 говорит, что «файлы журналов регистрации событий должны быть защищены от несанкционированных изменений». Это очевидно, поскольку, если журналы могут быть изменены неуполномоченным лицом, они не могут считаться объективной информацией о действиях пользователей и систем.
Однако это требует обеспечить защиту файлов журналов регистрации событий не только от неуполномоченных лиц, но и от системных сбоев, и от последствий ошибок при настройке систем. Это затрагивает не только целостность, но и доступность журналов регистрации событий. Эту тему продолжает требование п.10.5.3: «должно выполняться своевременное резервное копирование файлов журналов регистрации событий на централизованный лог-сервер или внешние носители информации, где эти файлы сложнее изменить». Организация централизованного хранения журналов регистрации событий на лог-сервере (одном или нескольких), на котором будет выполняться анализ собранных событий, очень важна, как для защиты журналов, так и для повышения эффективности их использования. Резервное копирование журналов регистрации событий на DVD-диски (или ленту) является еще одним следствием этого требования. Однако нужно понимать, что записанные на ленту или DVD-диски журналы не являются легко доступными, их неудобно использовать для поиска информации в случае инцидента, а PCI DSS требует сохранить возможность оперативного доступа к данным журналов регистрации событий в течение 3 месяцев.
Многие компоненты сетевой инфраструктуры, такие как маршрутизаторы, коммутаторы отправляют журналируемые события на внешний сервер, а на самом устройстве хранится только минимальный объем событий (или вообще не хранится). Для таких систем организация централизованного хранения журналов регистрации событий крайне важна. Кроме того, требование п.10.5.4 говорит, что необходимо «журналы регистрации событий доступных извне сетей и устройств (беспроводные сети, DNS, межсетевые экраны и т.п.) копировать на лог-сервер во внутренней сети».
Для дальнейшего снижения рисков несанкционированного изменения журналов регистрации событий, а также для обеспечения возможности доказать отсутствие каких-либо изменений, п.10.5.5 указывает, что «должно использоваться специальное программное обеспечение для контроля целостности файлов журналов регистрации событий и обнаружения изменений в них, обеспечивающее невозможность внесения изменений в данные журналов без генерации соответствующего предупреждения». При этом добавление в журнал новых событий не должно приводить к генерации такого предупреждения, т.к. в журналы регистрации событий постоянно добавляются новые события, их объем постоянно растет, а не уменьшается (за исключением периодической архивации старых событий на внешние носители информации и их удаления с сервера). Системы мониторинга целостности файлов используют криптографические алгоритмы хэширования для сравнения имеющихся файлов с заведомо правильной копией. Поскольку в файлы журналов регистрации событий постоянно записываются новые события, процесс постоянного расчета их хэш-функций может стать настоящей проблемой. Нужно понимать, что контроль целостности может проводиться только в отношении статичных файлов журналов регистрации событий, а не тех, в которые непрерывно добавляется новая информация. Существуют некоторые специальные алгоритмы, позволяющие выявлять любые изменения, кроме добавления.
10.6
Следующее требование является одним из самых важных, тем не менее, оно часто упускается из виду. Многие специалисты, внедряющие средства безопасности, необходимые для реализации требований PCI DSS, просто «забывают», что раздел 10 PCI DSS требует не только «иметь журналы регистрации событий», но и «контролировать их содержимое». В частности, в п.10.6 говорится, что «Просмотр журналов регистрации событий для всех системных компонентов должен выполняться не реже одного раза в день. Также должны просматриваться журналы регистрации событий серверов, выполняющих функции обеспечения безопасности (таких как системы обнаружения вторжений (IDS) и серверы аутентификации, авторизации и учета (AAA), например, RADIUS)». Далее в настоящем Руководстве процедуры и методы анализа журналов регистрации событий будут рассмотрены более подробно.Данное требование определяет системы, журналы регистрации событий с которых должны «просматриваться ежедневно», поэтому недостаточно просто настроить на них журналирование событий и организовать копирование или централизованное хранение журналов. Учитывая, что большая ИТ-среда может производить гигабайты журналов ежедневно, анализ каждого сохраненного в них события выходит за рамки человеческих возможностей. Именно поэтому в данном пункте PCI DSS сделано примечание, которое говорит, что «для достижения соответствия требованию 10.6 могут использоваться инструменты сбора, анализа событий и передачи уведомлений». Далее будут рассмотрены ручные и автоматизированные методы анализа журналов регистрации событий.
10.7
Последний пункт требований раздела 10 связан с еще одним важным вопросом журналирования событий – сохранением журналов регистрации событий в оперативном доступе. В п.10.7 сказано, что «журналы регистрации событий должны храниться не менее одного года, при этом в течение трех месяцев журналы должны находиться в режиме постоянной готовности для немедленного проведения анализа». Таким образом, если вы не можете просмотреть журналы регистрации событий годовой давности, это будет являться нарушением.Итак, подведем итог рассмотренных до настоящего момента требований PCI DSS в части журналирования событий:
- Раздел 10 PCI DSS устанавливает требования по ведению регистрации определенных событий и указывает уровень детализации сохраняемой в журналах информации. Эти требования распространяются на все системы, находящиеся в области действия PCI DSS.
- Необходимо обеспечить наличие связи между сохраненными в журналах действиями и конкретными пользователями.
- Системные часы на всех системах, входящих в область действия PCI DSS, должны быть синхронизированы.
- Необходимо обеспечить защиту конфиденциальности, целостности и доступности собранных журналов регистрации событий.
- Журналы регистрации событий должны регулярно просматриваться.
- Журналы регистрации событий всех систем, входящих в область действия PCI DSS, должны храниться не менее года.
Например, в разделе 1 «Обеспечить настройку и управление конфигурацией межсетевых экранов для обеспечения защиты данных платежных карт» говорится, что компании должны иметь «формализованный процесс утверждения и тестирования всех подключений внешних сетей, а также изменений, вносимых в конфигурацию межсетевых экранов и маршрутизаторов». Однако после создания такого процесса, необходимо иметь возможность подтверждения, что настройки межсетевых экранов и маршрутизаторов изменяются только после официального утверждения этих изменений и в строгом соответствии с документированными процедурами по управлению изменениями. Как раз для этой цели очень удобно использовать журналы регистрации событий, поскольку они показывают, что происходило на самом деле, а не только то, что должно было выполняться.
Пункт 1.3 (со всеми его подпунктами) содержит указания по настройке межсетевого экрана вплоть до конкретных требований в отношении входящих и исходящих соединений. Для того чтобы подтвердить реализацию этого требования, необходимо использовать журналы регистрации событий. Проведения анализа конфигурации межсетевого экрана будет недостаточно, поскольку только журналы могут сказать о том, «как межсетевой экран работал на самом деле», а не просто «как он был настроен».
Раздел 2 говорит о лучших практиках по управлению паролями, а также об общем укреплении безопасности, в частности, об отключении ненужных сервисов. Журналы регистрации событий могут показать, что эти ранее заблокированные сервисы вновь были включены неправильно проинструктированным системным администратором или злоумышленником.
Раздел 3, который указывает на необходимость шифрования данных, имеет прямые и недвусмысленные ссылки на журналирование событий. В частности, весь п.3.6 основан на наличии журналов регистрации событий, которые позволят проверить, что требуемые в этом пункте действия действительно выполняются. Такие процедуры, как генерация ключей, их распределение и отзыв, журналируются большинством криптографических систем. Наличие этих журналов имеет решающее значение для обеспечения соответствия этому требованию.
Соблюдение требований раздела 4, который также связан с шифрованием, по тем же причинам может быть подтверждено только с помощью журналов регистрации событий.
Раздел 5 относится к антивирусной защите. Разумеется, чтобы подтвердить выполнение указаний п.5.2, который говорит, что «средства антивирусной защиты должны быть постоянно включены, они должны регулярно обновляться и вести журналирование событий», потребуется продемонстрировать эти журналы.
Таким образом, даже требование «использовать и регулярно обновлять антивирусное программное обеспечение» ведет к необходимости ведения журналов регистрации событий, поскольку при проведении оценки соответствия требованиям PCI DSS данные этих журналов понадобятся для подтверждения их фактической реализации. Кроме того, в журналах будут отражаться факты неудачных попыток обновления антивируса, что подвергает компанию дополнительному риску заражения вирусами, т.к. антивирус с неактуальными базами вирусных сигнатур создает ложное чувство безопасности и сводит «на нет» усилия по обеспечению соответствия данным требованиям.
Раздел 6 говорит о необходимости «обеспечить безопасность при разработке и поддержке систем и приложений», что немыслимо без организации полноценной системы журналирования событий и контроля безопасности приложений.
Раздел 7, в котором указано, что необходимо «ограничить доступ к данным платежных карт в соответствии со служебной необходимостью», фактически требует вести журналы регистрации событий для проверки, кто в действительности получал доступ к указанным данным. Если в журнале будут обнаружены события получения доступа к данным платежных карт пользователями, которым такой доступ не требуется для выполнения своих обязанностей, требуется, как минимум, внести соответствующие изменения в настройки прав доступа.
Назначение каждому пользователю, использующему систему, уникального идентификатора соответствует «лучшим практикам» в области безопасности. В PCI DSS это не просто «лучшая практика» – это требование (раздел 8 – «каждому лицу, имеющему доступ к компьютерным ресурсам, должен быть назначен уникальный идентификатор»). Очевидно, что при этом необходимо «контролировать добавление, удаление и изменение учетных записей пользователей, учетных данных и других идентификационных объектов» (п.8.5.1 PCI DSS). Большинство систем записывают такие действия в журнал регистрации событий.
Кроме того, выполнение п.8.5.9, требующего «обеспечить изменение паролей пользователей не реже одного раза в 90 дней», также может быть проверено путем анализа содержимого журналов регистрации событий сервера, чтобы убедиться, что пароли всех учетных записей реально изменяются не реже одного раза в 90 дней.
Раздел 9 относится к другой области безопасности – физическому контролю доступа. Даже п.9.4, в котором говорится, что «Для хранения записей о посетителях должен использоваться журнал регистрации посетителей, в котором должны указываться ФИО посетителя, название компании, которую он представляет, и ФИО сотрудника компании, который дал разрешение на пропуск этого посетителя. Данный журнал должен храниться не менее 3 месяцев, если это не противоречит законодательству», может быть связан с управлением журналами регистрации событий, если этот журнал регистрации посетителей ведется в электронной форме.
Раздел 11 говорит о необходимости «регулярного тестирования систем и процессов обеспечения безопасности». Однако п.11.4 также требует использования систем IDS или IPS: «Должны использоваться системы выявления и/или предотвращения вторжений для мониторинга всего трафика на периметре среды, в которой хранятся и обрабатываются данные платежных карт, а также на критичных узлах внутри этой среды. Эти системы должны оповещать персонал о подозрительных действиях. Должно проводиться регулярное обновление программного обеспечения и сигнатур систем выявления и предотвращения вторжений». Польза от работы системы выявления вторжений будет только в том случае, если анализируются ее журналы регистрации событий и отправляемые ей оповещения.
Раздел 12 касается более высокоуровневых вопросов безопасности – политики безопасности, а также стандартов безопасности и ежедневных процедур (например, среди них должна быть процедура ежедневного анализа журналов регистрации событий, предусмотренная в Требовании 10). Однако этот раздел затрагивает также и вопросы журналирования событий, поскольку ведение журналов регистрации событий должно быть частью любой политики безопасности. Кроме того, требования в отношении реагирования на инциденты, также связаны с журналами регистрации событий – п.12.5.3: «разработка, документирование и распределение процедур реагирования на инциденты безопасности и процедур эскалации для обеспечения своевременной и эффективной обработки инцидентов в любых ситуациях» невозможно реализовать это без эффективного сбора и своевременного анализа данных журналов регистрации событий.
Таким образом, организация журналирования событий и ведения мониторинга содержимого журналов при внедрении PCI DSS, выходит далеко за рамки требований раздела 10. Только с помощью тщательного сбора и анализа журналов регистрации событий компания сможет обеспечить свое соответствие большинству требований PCI DSS.
dorlov.blogspot.com
Информационная безопасность: Полезные сайты и инструменты
Обновлено: 12.02.2012
Полезные сайты по ИБ- Anti-Malware (информационно-аналитический сайт по ИБ, основная тема - антивирусы и их исследования; есть форум)
- AuditNet (все об аудите ИТ и ИБ)
- CCCure (обучение по ИБ, сертификация, тестирование, аналитика, лучшие практики, документы)
- CERT (информация об уязвимостях, аналитика, исследования, лучшие практики, проведение расследований)
- Datum (сайт Ассоциации защиты прав операторов и субъектов персональных данных)
- Information Security Forum (лучшие практики, исследования, отчеты, методологии)
- ISO27000.ru (портал по ИБ, аналитика, информация по законодательству и стандартам, блоги, каталоги ресурсов и ПО)
- NIST - Национальный институт стандартов и технологий США (лучшие практики, публикации на тему ИБ, материалы исследований)
- SANS (лучшие практики, статьи, исследования, информация об угрозах и уязвимостях)
- Secunia (информация об уязвимостях)
- Security Focus (информация об угрозах и уязвимостях, новости, средства обеспечения и анализа безопасности)
- Security Lab (новости, информация об угрозах и уязвимостях, статьи, средства обеспечения и анализа безопасности)
- SecurityManagement.ru (форум по ИБ)
- SecurityPolicy.RU (открытая библиотека документов по ИБ)
- the Center for Internet Security (средства анализа безопасности, лучшие практики, чек-листы)
- wikIsec - Энциклопедия информационной безопасности (публикации, статьи)
- Windows IT Pro/RE (раздел по безопасности русского издания журнала)
- WinSecurity.ru (статьи, документация, новости по безопасности Windows)
- Журнал Информационная безопасность (публикации, статьи, обзоры, форум)
- Раздел форума по ИБ на сайте Bankir.ru (форум по ИБ)
- Центр безопасности Microsoft TechNet (рекомендации, обновления, средства обеспечения и анализа безопасности)
dorlov.blogspot.com
6 декабря, 2016«BIS Journal» № 4(23)/2016 заместитель директора Департамента ИБ (АМТ-ГРУП) Как фильтровать маркетинговые тренды
Например, развитие межсетевых экранов шло по пути (упрощенно): Stateless (packet) Firewall -> Statefull Firewall-> UTM firewall -> Application Firewall -> Next Generation Firewall. На мой взгляд, это показательный пример эволюционного развития одного класса решений ИБ. Нужно ли менять удовлетворительно работающий UTM на NGFW? Далеко не всегда. Являются ли новые функции NGFW необходимыми? Как правило, они полезны, но не необходимы даже с поправкой на особую модель угроз: IPS и потоковый антивирус в составе UTM тоже делает инспекцию приложений, пусть и без набора функций NGFW. Также давайте вспомним про внезапный рост популярности такого явления как APT (Advanced Persistent Threat) и развития “специализированных” решений борьбы с APT. А раньше APT не было? Угрозы, конечно, каждый год растут, но это касается любого типа угроз. И разве бывают IPS, не противодействующие APT – таргетированным и сложным атакам? Так или иначе любое средство ИБ в какой-то степени разработано для борьбы с APT. Глобальная задача любого решения ИБ одна: обнаруживать и подавлять злонамеренную активность, как обособленную, так и в составе сложной APT-атаки. Поэтому менять корректно настроенный и обновляющийся (сигнатурные базы) сигнатурный IPS на сигнатурный APT IPS в большинстве случаев не представляется необходимым. Это не камень в огород маркетинга, это жизнь и, вообще, нужно честно признаться, что главным драйвером развития ИБ являются, в первую очередь, не объективные угрозы, а рынок и продажи (в свою очередь, только косвенно зависимые от тех самых угроз). В этом контексте хотелось бы подвести некоторую черту и оценить современный (существующий) рынок ИБ с целью поиска наиболее эффективных, инновационных решений ИБ для службы SOC. При этом, разумеется, я не беру в расчет комплекс необходимых и уже традиционных технических мер (межсетевые экраны, антивирусы, сканеры уязвимостей, системы предотвращения вторжений и некоторые другие), которые хорошо зарекомендовали себя лет двадцать назад и остаются актуальными, понемногу эволюционируя. Точно так, как и не говорю о специализированных решениях для защиты конкретных систем (защита баз данных и Web, Honeypot и др.). Ниже мой список наиболее эффективных, “must have” решений и технологий SOС:
| Мы в социальных сетяхСобытияПн Вт Ср Чт Пт Сб Вс 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30  |

journal.ib-bank.ru