Это интересно
- ОКД
- ЗКС
- ИПО
- КНПВ
- Мондиоринг
- Большой ринг
- Французский ринг
- Аджилити
- Фризби
Опрос
Полезные ссылки
РКФ

Все о дрессировке собак

Стрижка собак в Коломне

Поиск по сайту
Как быстро отсканировать книгу в формат PDF (используя ClearScan), стр. 1. Как отсканировать журнал в pdf чтобы листались листы
Как быстро отсканировать книгу в формат PDF (используя ClearScan) | Проза жизни
ВВЕДЕНИЕ
В этом кратком пособии я бы хотел поделиться своим мыслями о сканировании книг в формат PDF и впечатлениями о технологии ClearScan, доступной в Adobe Acrobat начиная с версии 9.0. На мой взгляд, это замечательная технология, делающая (наконец-то!) формат PDF подходящим для отсканированного текста.
Фактически, при деструктивном сканировании (книга разрывается на листы и используется листовой сканер), процесс сканирования → чистки → перевода в PDF → OCR можно выполнить за тройку часов для чёрно-белой книги среднего размера. Если же вы «стекольщик», то есть у вас достаточно терпения сканировать книгу на стекле сканера, сканирование, очевидно, займёт дольше.
Надо сказать что хорошо отсканировать цветную книгу сложнее чем чёрно-белую: сканер портит цвета, и на их исправление в графическом редакторе уходит время и требуется определённый навык. Можно представить себе такую шкалу сложности, в начале которой находятся самые простые для сканирования книги с чёрно-белым текстом без иллюстраций; постепенно, иллюстраций становится всё больше, прибавляется цвет, так что на другой стороне этой шкалы находятся самые сложные для сканирования книги у которых каждая страница — цветная иллюстрация.
Технология ClearScan, о которой я расскажу, рассчитана на текст. Она никак не влияет на иллюстрации, чёрно-белые или цветные. Если вы захотите узнать о сканировании подробнее, и/или вы собираетесь сканировать книги с большим количеством цветных иллюстраций и хотите уметь исправлять их цвета, то я могу дать ссылку на пособие по сканированию книг в высоком качестве, размещённое в библиотеке Twirpx.com, которое также включает в себя инструкции по работе с программой Photoshop:
www.twirpx.com/file/1437636/
Моя задача скромнее. Я предполагаю у вас наличие книги, где основные страницы — текст. Это может быть учебник или документ, художественная литература или техническая, но не детская книжка с картинками, не книжка-фоторепортаж. Я рассчитываю что вы хотите перевести такую книгу в PDF и получить приличное качество и небольшой размер файла.
КАК СКАНИРУЕТ НАЧИНАЮЩИЙ
Если есть сканер, то хочется что-нибудь отсканировать! И слава Богу. Посмотрите на обилие электронных библиотек. Спасибо всем кто отсканировал и выложил это для других.
Сканеры сегодня продаются с пакетом программ, среди которых есть и программа по преобразованию в PDF. В теории (и в рекламных проспектах) это выглядит так: заложи в сканер листы, получи их на выходе в электронном виде, в формате PDF! И это иногда правда. Есть большое количество разных бумаг (количеством 1, 2, … 10 листов) с которыми я так и поступаю. А чего с ними чикаться? Видно — будет. А большее и не нужно. Но вот книга… да ещё для тех, кто любит книги… разве можно назвать получившуюся косую дрянь с полосами, пятнами, чёрными точками, с разорванным шрифтом книгой? Где же зарыта собака? Какую опцию надо выставить, какой рычажок покрутить, чтобы всё это стало похоже на оригинал?
В том-то и дело что нет такого одного рычажка. Есть четырёхступенчатый процесс, каждая ступень которого требует некоторых оптимальных решений от оператора. Пакет программ для сканера, работающий по типу «одним махом всех побивахом», скрывает этот четырёхступенчатый процесс, делая из него одну операцию: бумажный лист → электронный эквивалент. Но о том что на самом деле происходит что-то сложное, всё же можно догадаться. Например, сканер уже закончил сканировать, а компьютер ещё не готов продолжать; на нём открываются и закрываются какие-то программы; мигает лампочка доступа к жёсткому диску… Чтобы отсканировать книгу качественно, надо самому пройтись по ступеням этого процесса: сканирование, чистка, перевод в нужный формат и распознавание текста (OCR).
1. СКАНИРОВАНИЕ
Задача этой ступени перевести бумажные страницы книги в соответствующие им файлы в формате TIFF с разрешением как минимум 300 dpi. Это разрешение достаточно для книжного текста обычного («читабельного») размера. Мелкий шрифт или желание передать мелкие детали иллюстраций может потребовать большего разрешения. Покопайтесь в настройках своего сканера. На выходе, вам нужно получить графические файлы, в формате TIFF. Один лист — один файл. И никаких многостраничных TIFF-ов (где в одном TIFF файле несколько страниц)! Никаких PDF-ов! Никаких OCR-ов (распознаваний текста)!
На этой ступени также нужно принять решение о сканировании книге в цвете (color) или в оттенках серого (grayscale). Обычно не рекомендуется сканировать книгу в строго чёрно-белом варианте (b&w), даже если книга чёрно-белая, так как сканер должен будет тогда решать что делать чёрным, а что белым. Скажем, изгиб на странице может быть передан чёрным и создаст чёрные полосы и пятна, а ещё того хуже, эти пятна закроют чёрный же текст. Вычистить потом такое «чёрное на чёрном» невозможно. Если же пятно (полоса, другой дефект) серого (или другого, при цветном сканировании) цвета, а текст чёрного (отличного от дефекта) цвета, то дефект можно будет убрать на стадии чистки путём удаления из изображения цвета пятна. Поэтому книжки с пожелтевшими страницами хорошо сканировать в цвете, чтобы иметь возможность убрать жёлтый цвет из получившегося скана. Бывает также, строго чёрно-белое сканирование утоньшает и разрывает линии и шрифт (то есть когда буква, скажем, «d» выглядит как «cl»). Поэтому, для качественного сканирования, не стоит сканировать в строго чёрно-белом варианте (b&w). Никто не запрещает перевести страницу в чёрно-белое изображение потом, когда изображение почищено, если такой перевод нужен. Как мы увидим, для технологии ClearScan такой перевод не требуется: ClearScan прекрасно работает с текстом в оттенках серого и с большим разрешением.
Для моего листового сканера, сканирование начинается с отрезания обложки. Обычный кухонный нож с коротким лезвием и удобной ручкой вполне подойдёт. Для мягкой обложки, нож просовывается между обложкой и первой страницей (при закрытой обложке) и обложка отрезается. Если у книги твёрдая обложка, то при открытой обложке из неё вырезается сама книга. Страницы потом либо отрываются по одной, либо отрезаются. Рваные края потом можно будет удалить с помощью программы на стадии чистки. Главное, чтобы рваные края не залезали на текст.
Пишу эти строки, а в голове звучит стихотворение Маршака:
У Скворцова ГришкиЖили-были книжки —Грязные, лохматые,Рваные, горбатые…
У меня есть книжки, ещё из детства, которые я люблю и не буду резать. Но часто приходится сканировать пособия, часто компьютерные, часто толстые, и макулатура — лучшее место для них. И времени своего на сканирование «на стекле» жаль тратить.
Ещё раз о базовых настройках сканера. Разрешение — 300 dpi или больше, цветовой режим «оттенки серого» (grayscale) или «цветной» (color). Формат файла — TIFF. Измерив страницу книги в миллиметрах, можно задать длину и ширину. Конечно, «на стекле» это можно сделать лишь приблизительно, так как точно положить книгу на стекло невозможно. А листовой сканер будет засасывать листы с ровной стороны (либо сверху/снизу либо, если сбоку, надо положить ровной стороной) и тут всё будет точно вплоть до миллиметра. На своём листовом сканере я, последнее время, из-за врождённой лени, выбираю опцию «улучшить текст» (text enhancement), которая «ужирняет» и «учерняет» текст и портит цветные иллюстрации (сгущает краски) и опцию «выравнять изображения» (deskew) так как ровные листы легче потом обработать. Но можно вообще никаких других опций кроме dpi и цвета не выбирать, и оставить всё остальное на стадию чистки.
2. ЧИСТКА
Задача этой ступени — получить на выходе файлы с чистыми, красивыми страницами в том же формате TIFF и в том же количестве. Это «набор» будущей электронной книги. Нечего и говорить, что обрабатывать нужно все (вернее почти все) изображения по группам, т. е. в «пакетном режиме» (batch processing). Кроме обложек и некоторых других неординарных страниц, возиться с каждым изображением страницы отдельно в графическом редакторе практически невозможно (представьте 700 страниц текста!) да и не нужно.
Для чистки, я раньше пользовался программой ScanKromsator v5.9. Её можно найти в интернете.
Ссылки на описание этой программы:
ru.wikipedia.org/wiki/ScanKromsatorwww.djvu-soft.narod.ru/kromsator/www.twirpx.com/file/394016/
Программа, особенно для начинающего, сложная из-за непривычного интерфейса, большого количества опций и плохой документации. Не всегда понятно какой же результат будет в конце. Последнее время, я пользуюсь комбинацией программ Photoshop и Scan Tailor. Scan Tailor не пытается быть графическим редактором как ScanKromsator, но из-за этого им проще пользоваться. Объединив же возможности программ Photoshop и Scan Tailor, набирается внушительный инструментарий для выправления сырых сканов. Документация к Scan Tailor есть здесь:
sourceforge.net/apps/mediawiki/scantailor/index.php?title=Main_Page
Какая бы программа не использовалась, нужно
убрать наклон страниц (deskew)отрезать неровные краявыравнять освещённость (убрать тени от неравномерной освещённости)убрать точки и другой мусор (despeckle)отдельно проверить/выправить иллюстрации (включая обложку)
Можно поправить такие дефекты на станицах как заметки на полях (если конечно, нет цели их сохранить), стереть карандашные линии, подчёркивающие текст (будут мешать программе OCR, которая примет их за графику), убрать полосы, пятна, а иногда и задний фон. Я однажды сканировал книжку с синими буквами на голубом фоне; фон вышел безобразно, и я его просто убрал, т. е. поменял на белый, благо он был чуть светлее текста и от него можно было избавиться, убрав его цвета.
Из вышесказанного ясно, что чистка — это самая технически сложная ступень. Если вы не работали раньше с графическими редакторами, то нечего и думать сделать всё с первого раза на сто процентов. Не отчаиваетесь! Даже чуть облагороженный файл — это шаг вперёд на пути к лучше отсканированной книге! В другой раз будет ещё лучше. А потом, русские просто обожают чистку! К сожалению, мы даже любим вычищать наше собственное население. Или, как говорят теперь, «зачищать». Было вычищено столько народу, что если б от этого действительно зависело продвижение на пути в рай, мы давно жили б в раю. Как тут не вспомнить Сергея Мироновича Кирова:
«ЧК-ГПУ — это орган, призванный карать, а если попросту изобразить это дело, — не только карать, а карать по-настоящему, чтобы на том свете был заметен прирост населения, благодаря деятельности нашего ГПУ.»
На том свете, стало быть прибыло, а на этом убыло. Но они ж все плохие были, те которые убыли… чего их не расстрелять за плохоту? Простите за отступление, просто в нашем стремлении к крайностям мы иногда вычищаем самих себя. Потом удивляемся: «почему у нас режим авторитарный?» Потому что хочется быстрых, кардинальных, простых решений для сложных проблем. Посмотрите сколько людей мыслят в русле «да взять их всех да и [способ вычищения]», и вы согласитесь что никакого другого режима, кроме авторитарного, т. е. который способен «всех взять за … и …» нам не светит.
3. ПЕРЕВОД В КОНЕЧНЫЙ ФОРМАТ
Итак… переводим книгу в нужный формат. Я здесь рассматриваю только формат PDF как единственно простое, быстрое, кардинальное решение «форматного вопроса»… стойте. Где-то я уже это говорил. Ах, да. Ну, хорошо, есть много форматов в которые можно перевести книгу, в том числе «текстовые», то есть такие где распознанный текст отделяется от книги и публикуется без неё. Программа по распознаванию текста ошибается, и такому отделённому тексту нужна хорошая вычитка. Но нравится вам вычитывать книгу — вычитывайте. Только уж вычитывайте как следует, а то скачаешь с интернета книжку в текстовом формате — там опечаток море.
Я же объясню как сделать книгу в PDF, причём используя технологию ClearScan. ClearScan — передовая технология. Если сам по себе формат PDF не идеален для хранения отсканированного текста (получается либо большого размера файл, либо, если сжать побольше, некачественное изображение) то при применении ClearScan, этот формат приближается к идеальному.
На самом деле, принципиальных вариантов что делать с отсканированной книгой не так много. Можно просто оставить её в TIFF файлах. Кстати, эти файлы можно оставить в любом случае. Как уже было сказано, TIFF файлы — «набор» книги. Из них потом можно лепить другие форматы. Мне лень их хранить, но потом не раз я покусал локотки из-за того что оригиналов уже не было. Однако, TIFF файлы не удобны для обмена. Они занимают много места, и смотреть их надо в графическом редакторе. Можно перевести TIFF файлы в формат JPEG, так они займут меньше места. Но формат JPEG не лучший вариант для чёрно-белого текста, особенно когда его несколько сот страниц.
Можно перевести книгу в текстовой или смешанный формат: TXT, RTF, DOC наконец, или в HTML-ные и XML-ные EPUB и FB2. Но это — отделить текст и переиздать книжку заново. И возможно, потерять всё или часть оформления книжки при переиздании. Нужно ли это, если книжка уже издана? Конечно, решать вам. Если оформления немного, то можно и переиздать. А если много и его хочется сохранить? Да и просто не хочется терять время на переиздание? Тогда остаётся либо «хлопнуть» книгу в DJVU, либо в PDF (кто-то «хлопает» и в PowerPoint, но это уж, простите, «ваще»).
В теории, до появления технологии ClearScan, формат DJVU больше подходил для отсканированных книг чем PDF, так как файлы получались меньше. Но на практике, PDF куда более распространён (это факт), а программы позволяющие читать PDF куда более привлекательны (это моё мнение) чем-то что создано для DJVU, что для меня выбор был ясен даже до появления технологии ClearScan. А теперь-то уж…
Суть технологии ClearScan состоит в замене изображений букв на стадии OCR на настоящий шрифт. Этот шрифт не является каким-либо готовым (системным) шрифтом более-менее похожим на оригинальный шрифт, а специальным шрифтом изготавливаемым программой Acrobat «на лету» под конкретную букву текста.
В результате, вместо страницы книги в графическом формате, появляется страница с (почти) настоящим текстом, по форме (почти) таким же как и оригинальный.
Ссылка на статью на английском языке о технологии ClearScan:
blogs.adobe.com/acrolaw/2009/05/better_pdf_ocr_clearscan_is_smal/
Как сказано в этой статье и проверенно на практике, самые лучшие результаты получаются при высоком разрешении оригинала (600dpi) и отсутствии на оригинале побочных помех (мусора, артефактов).
Где же взять Adobe Acrobat 9.0 и выше? В голове тут же начинает крутиться одно [нехорошее слово]. Но зачем мне учить вас нехорошим словам? Вы их знаете и без меня. Поэтому, как экзотический альтернативный способ, я придумал зайти на какой-нибудь аукцион, скажем E-bay, набрать adobe acrobat 9 pro и посмотреть можно ли получить то что хочется по разумной цене. Допустим — можно. И Acrobat у вас.
Запустив Acrobat, выбираем все TIFF-ы получившиеся после чистки. Для этого жмём на File → Combine → Merge Files into a Single PDF. Открывается окошко в котором мы справа вверху выбираем опцию Single PDF (она скорей всего и так выбрана). Нажимаем Add Files → Add Files и добавляем все TIFF-ы. Чтобы добавить все файлы сразу, нажимаем мышкой на первый файл, потом держим клавишу Shift и нажимаем на последний файл. Нажимаем Combine Files и терпеливо ждём результата — одного файла в формате PDF.
4. OCR С ОПЦИЕЙ CLEARSCAN
Это самая простая для нас ступень. Bo-первых, распознать текст (OCR) нужно для того, чтобы заменить изображения букв на шрифт (ClearScan). Во-вторых, если текст распознан, появляется возможность поиска по ключевым словам. Это удобно в учебниках, справочниках, да возможно и в художественной литературе. OCR не работает на сто процентов, и распознаёт текст не совсем верно. Но нам-то этого и не нужно. Мы не собираемся отделить этот распознанный текст от книги и опубликовать только его — это дело тех, кто выбрал текстовой формат. Аккуратность нам нужна только для поиска по ключевым словам, а для этой цели аккуратности OCR обычно хватает. Представьте себе какой-нибудь раздел в учебнике. Скажем, про постоянный ток. Сначала пойдёт заглавие — «постоянный ток». Потом определение постоянного тока. Потом свойства постоянного тока. Комбинация слов «постоянный ток» встретится в этом разделе много раз, и даже если OCR ошибётся однажды, второй случай употребления не останется незамеченным, и ваш поиск по ключевым словам «постоянный ток» приведёт в нужный раздел.
Что ж, запускаем OCR в том же Adobe Acrobat. Для этого делаем Document → OCR Text Recognition → Recognize Text Using OCR и в открывшимся окне нажимаем Edit в разделе Settings. Выбираем
Primary OCR Language — надо указать основной язык документаPDF Output Style — ставим ClearScanDownsample Images — обычно можно Low (300dpi)
Эта последняя настройка отвечает за заключительное разрешение нераспознанных изображений. Допустим, что вы отсканировали книгу в 600 dpi чтобы текст после ClearScan выглядел наилучшим образом. Но у вас в книге есть не только текст, но и иллюстрации. Они тоже оказались отсканированы в 600 dpi. Допустим также, что вы не хотите такого высокого разрешения для иллюстраций, так как вашим конкретным иллюстрациям это не нужно, а места при разрешении 600 dpi они будут занимать много. Выставив настройку Downsample Images, у вас есть возможность понизить разрешение иллюстраций в документе.
Ждём ещё терпеливей прежнего, а лучше идём отдыхать. На выходе получается искомый PDF. Найдите в нём какую-нибудь буковку и начните увеличивать. Эта буковка должна оставаться чёткой при любом увеличении.
Готово. Не забываем сохранить файл.
И вот что ещё… Не надо дожимать-пережимать этот файл в Acrobat-е ради экономии места на диске. Я даже не буду рассказывать как это сделать. Не надо портить качество файла, да и на мобильных устройствах, где процессор послабее, и программа для просматривания PDF не такая умная, смотреть такую пережатую книжку — мученье.
Попробуйте закинуть вашу книжку на мобильное устройство — для меня это будет iPad с читалкой iBooks. Как хорошо она выглядит! Как быстро можно листать страницы! Есть поиск по ключевым словам! Студенты! Отсканируйте свои учебники! Мамы и папы! Пожалуйста, отсканируйте хорошие детские книжки с картинками!
И, не забудьте выложить их в электронной библиотеке.
написал товарищ Кузнецов, Иван Иванович,со слов товарища Петрова Филиппа Фёдоровича,который услышал всё это от серой мышки.2012 — 2014 г.
shkolazhizni.ru
Как быстро отсканировать большой документ в один PDF "чужим" сканером
Сканировать документы в PDF — дело само по себе хлопотное и не быстрое, тем более, если надо оперативно отсканить сразу несколько страниц в один файл.
… и в особенности, если под рукой не оказалось более-менее современного сканера с устройством автоматической подачи оригиналов.
А если сканер вообще «чужой», то приходится изучать все нюансы процесса прямо на ходу, поскольку у каждой такой машинки бывают свои причуды.
К примеру, у HP без устройства автоподачи оригиналов надо сначала найти и открыть приложение HP Scan на компе, в нем выбрать опцию «Сохранить как PDF» и только потом запускать сканирование. При этом надо еще не забыть кликнуть кнопку «добавить…» после загрузки каждой новой страницы и «Сохранить» — в самом конце процедуры.
И у HP, надо сказать, не так всё и сложно. Бывает и сложнее. Потому опытные юзеры, если им приходится работать с незнакомыми сканерами, предпочитают популярное приложение naps2.
Прога бесплатная, очень проста (интерфейс на русском, к слову) весит мало и скачивается быстро. Предусмотрена в том числе и портативная версия, которая работает без установки. NAPS2 поддерживает оптическое распознавание символов (OCR) на любом из более чем сотни языков и позволяет не только сканировать и распознавать документы в один клик, но и редактировать готовые PDF (поворот, образка, изменение разрешения, контрастности, яркости и прочих параметров), поворачивать страницы, менять их порядок и тут же отправлять их по почте.
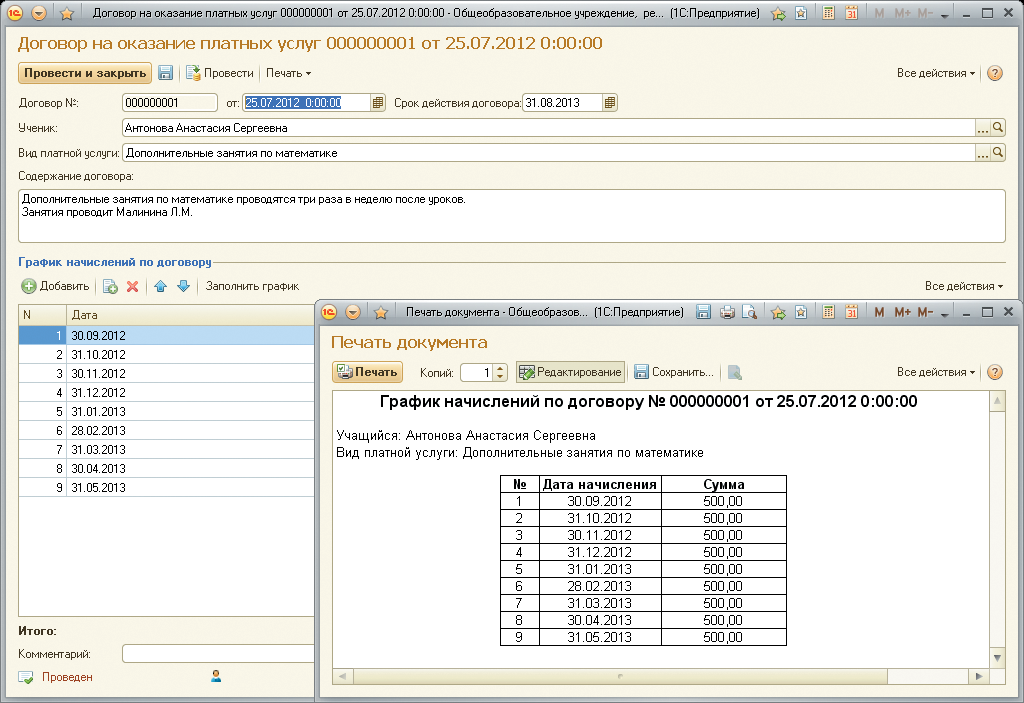
NAPS2 также удобна тем, что одинаково качественно работает как со «стекла», так и с автоподатчика (в т.ч. и «дуплекса»), совместима с WIA- и TWAIN-сканерами, может сохранять копии не только в PDF, но и в TIFF, JPEG, PNG и прочих форматах. Плюс к этому, предусмотрены также интерфейс командной строки (опционально) и MSI-установщик — для продвинутых пользователей.
И самое главное, с помощью NAPS2 можно легко и просто сканить документы в один PDF. Даже с незнакомого сканера и/или незнакомого компа и даже без установки самого приложения (если юзать портативную версию). В режиме «Пакетного сканирования» переключение на следующую страницу происходит автоматом (время задержки задать можно заранее). Так удобно сканить многостраничные документа, листая страницы друг за дружкой. Сняв последнюю, жмем «Сохранить» и приложение соберет все копии в один PDF-файл.
www.gadgetstyle.com.ua
Как сканировать в один файл PDF

Сканировать несколько страниц документов можно многими способами, после этого сохраняя их в различных форматах для дальнейшего использования. В рамках данной статьи мы расскажем, как сохранить отсканированный материал в один PDF-файл.
Сканирование в один PDF
Дальнейшая инструкция позволит вам отсканировать несколько страниц документов в один файл с помощью обычного сканера. Единственное, что вам потребуется – специальный софт, предоставляющий возможности не только сканирования, но и сохранения материала в PDF-файл.
Читайте также: Программы для сканирования документов
Способ 1: Scan2PDF
Программа Scan2PDF предоставляет все необходимые инструменты, позволяющие выполнить сканирование и сохранение страниц в единый PDF-документ. Софтом поддерживаются любые устройства для сканирования, приобретение лицензии не требуется.
Скачать программу с официального сайта
- Откройте страницу по представленной нами ссылке и выберите из списка пункт «Scan2PDF». Программу необходимо загрузить на компьютер и установить.
- Завершив процесс установки и открыв Scan2PDF, для удобства можно поменять язык интерфейса на «Русский» через раздел «Настройки».
- Раскройте список «Сканировать» и перейдите к окну «Выбрать сканер».
- Из данного списка вам необходимо выбрать устройство, которое будет использоваться в качестве источника.
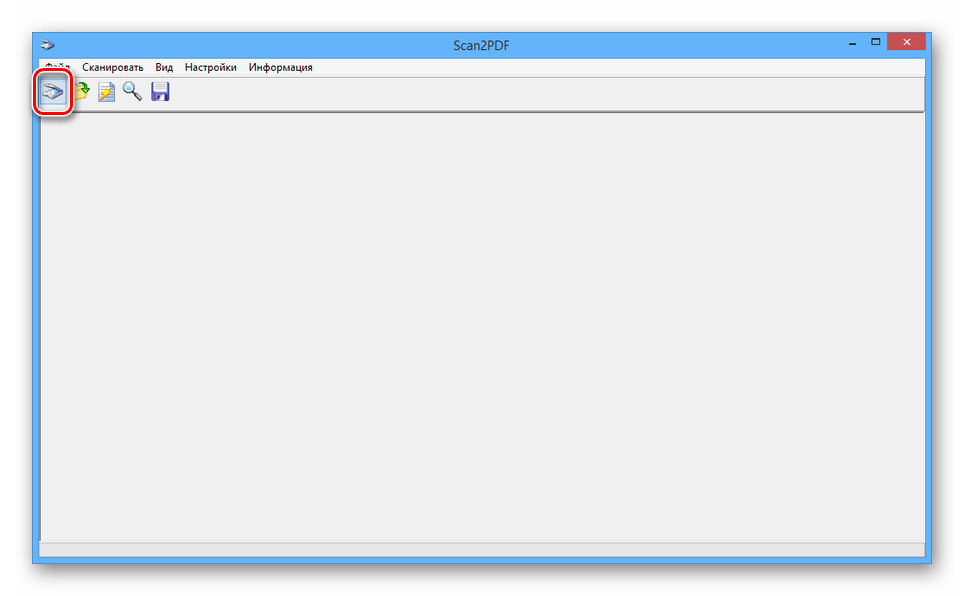
- После этого на панели инструментов или через тот же список кликните по кнопке «Сканировать».
- Укажите количество добавляемых страниц и выполните сканирование. Мы не будем заострять внимание на данном шаге, так как действия могут отличаться при использовании разных моделей устройств.
- При успешном сканировании в окне программы появятся нужные вам страницы. В меню «Вид» присутствует три дополнительных инструмента для обработки материала:

- «Свойства страницы» – для редактирования содержимого, включая фон и текст;
- «Изображения» – для открытия окна с добавленными сканами;
- «Профессиональный режим» – для одновременной работы со всеми инструментами.

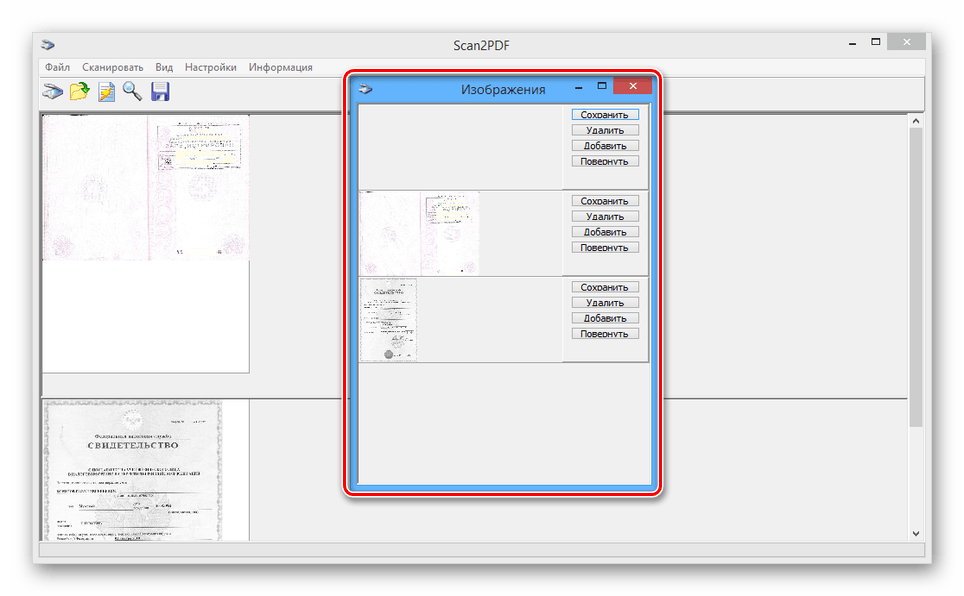
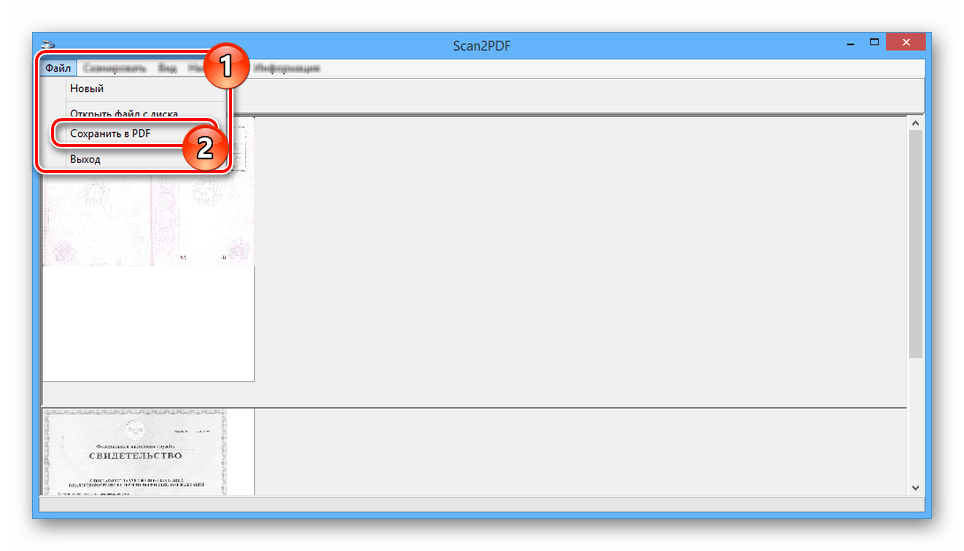
- Откройте список «Файл» и выберите пункт «Сохранить в PDF».
- Выберите место на компьютере и нажмите кнопку «Сохранить».

Готовый PDF-документ автоматически включает в себя все добавленные страницы.




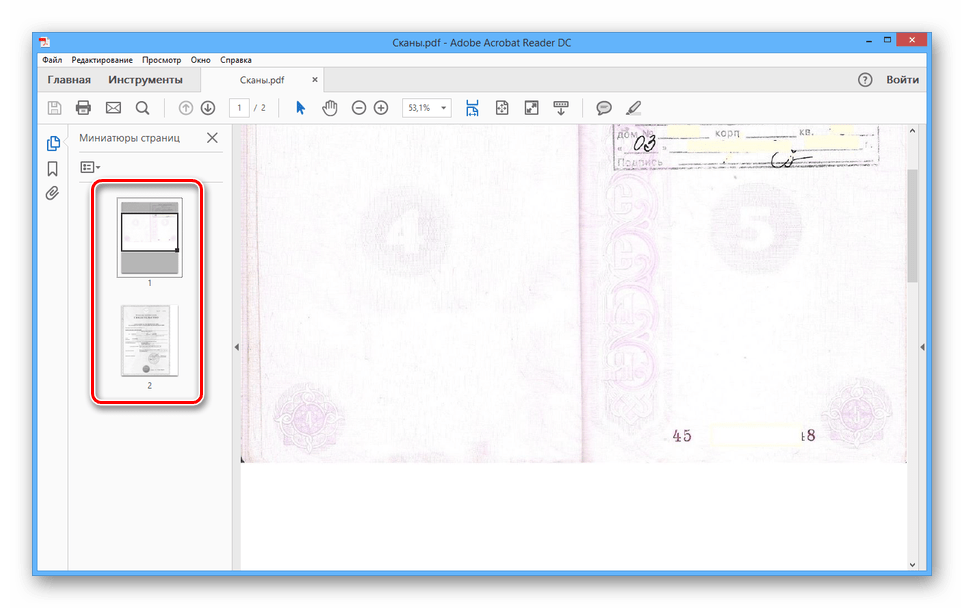
Программа обладает высокой скоростью обработки файлов и позволяет создать PDF-файл из отсканированного материала в несколько кликов. Однако в некоторых случаях количества предоставляемых инструментов может быть недостаточно.
Способ 2: RiDoc
Помимо рассмотренной выше программы, вы можете воспользоваться RiDoc – софтом, представляющим возможность склейки нескольких отсканированных страниц в один файл. Более подробно об особенностях данного ПО нами было рассказано в соответствующей статье на сайте.
Скачать RiDoc
- Следуя инструкции из материала по ссылке ниже, выполните сканирование документов, загрузив и подготовив страницы в программе.
Подробнее: Как отсканировать документ в RiDoc
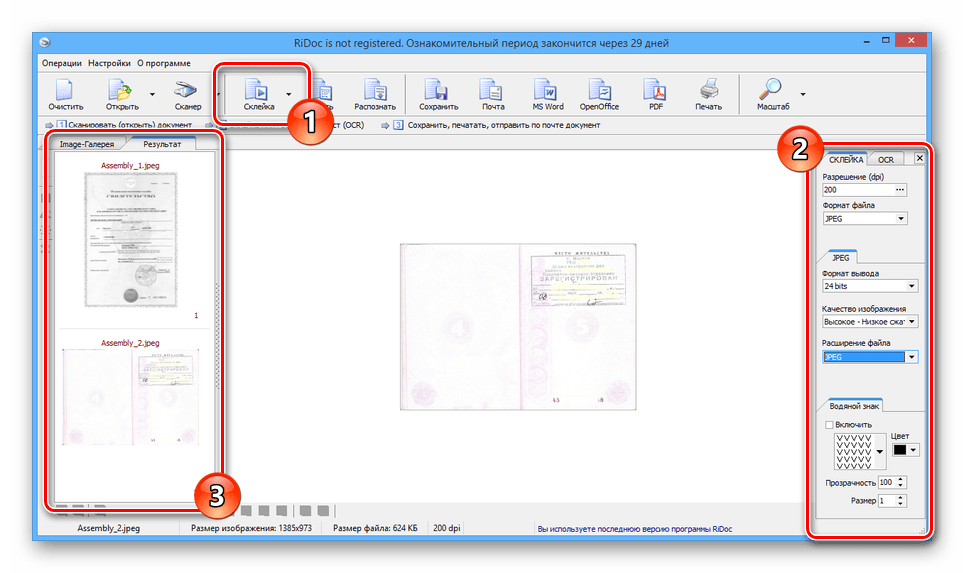
- Выделите добавляемые в PDF-файл изображения и на верхней панели инструментов кликните по значку с подписью «Склейка». По необходимости через одноименное меню измените основные параметры изображений.
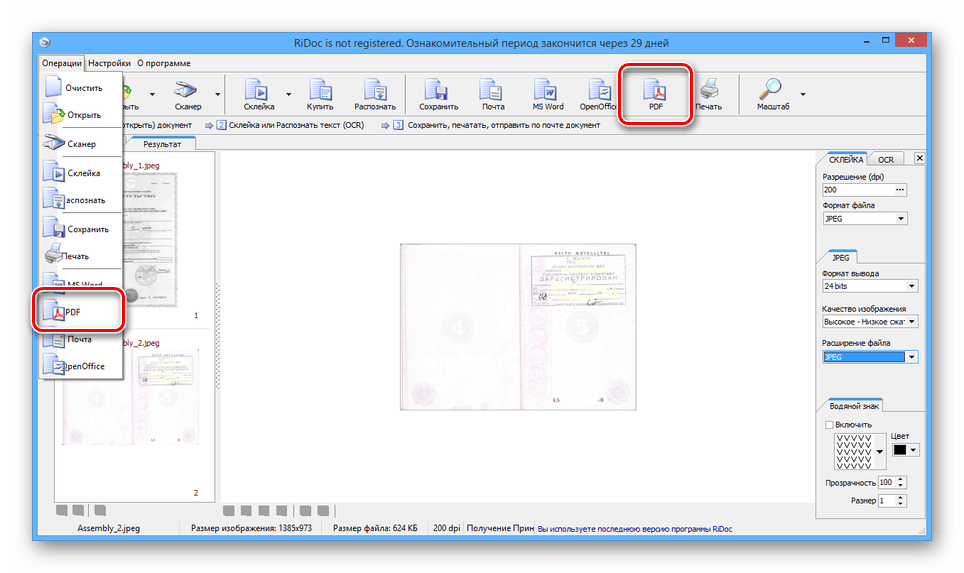
- После этого нажмите кнопку «Сохранить в PDF» на той же панели или в меню «Операции».
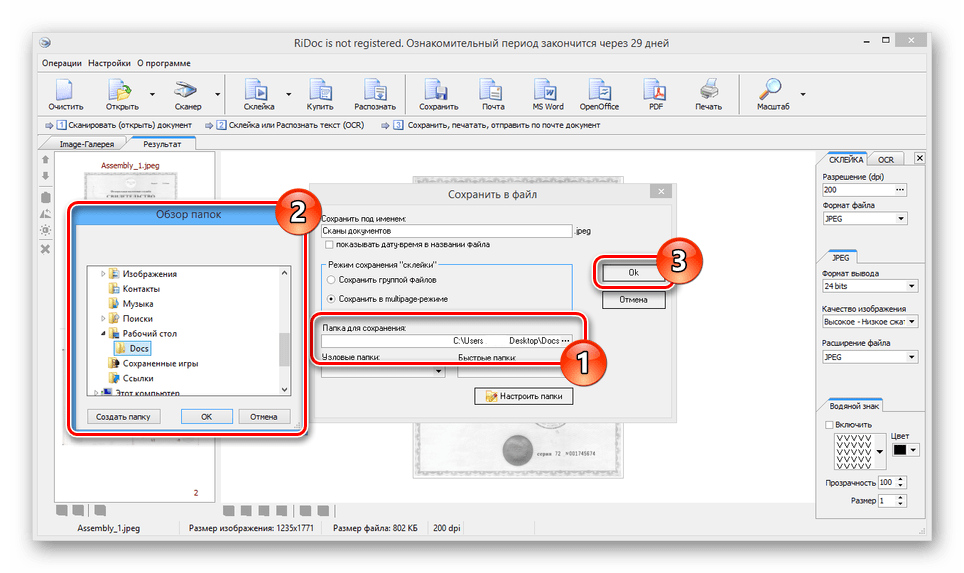
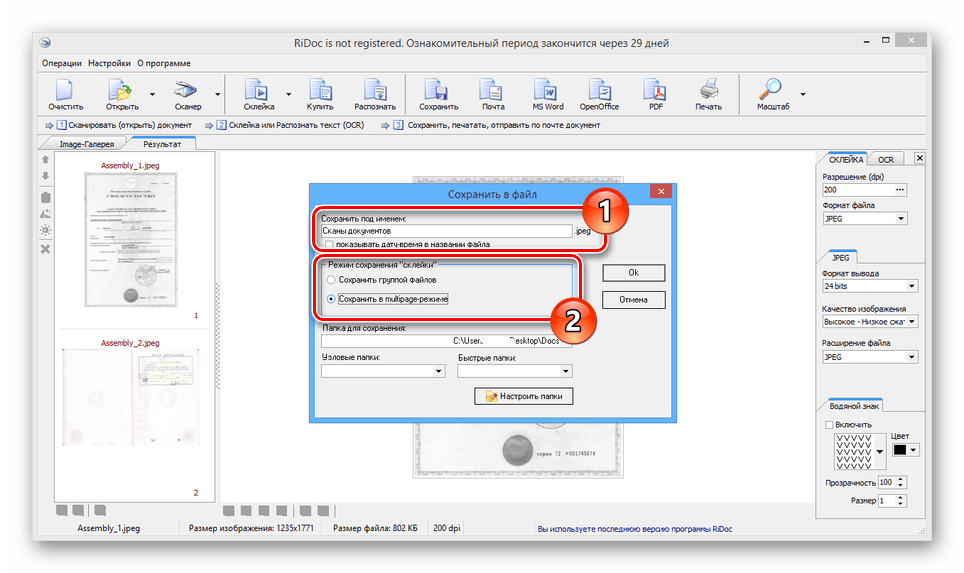
- В окне «Сохранить в файл» измените автоматически присвоенное имя и установите маркер рядом с пунктом «Сохранить в multipage-режиме».
- Измените значение в блоке «Папка для сохранения», указав подходящую директорию. Прочие параметры можно оставить в стандартном виде, нажав кнопку «Ok».
Если действия из инструкции были выполнены правильно, сохраненный PDF-документ автоматически откроется. Он будет состоять из всех подготовленных сканов.


Единственным недостатком программы является необходимость покупки лицензии. Однако несмотря на это, можно использовать софт в течение 30-дневного ознакомительного периода с доступом ко всем инструментам и без назойливой рекламы.
Читайте также: Объединение нескольких файлов в один PDF
Заключение
Рассмотренные программы сильно отличаются друг от друга в плане функционала, но одинаково хорошо справляются с поставленной задачей. В случае возникновения вопросов по данной инструкции, пишите их в комментариях.
 Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро. Помогла ли вам эта статья?
Да Нетlumpics.ru
Читать Как быстро отсканировать книгу в формат PDF (используя ClearScan) - Кузнецов Иван - Страница 1
И. И. Кузнецов
Как быстро отсканировать книгу в формат PDF (используя ClearScan)
Введение
В этом кратком пособии я бы хотел поделиться своим мыслями о быстром сканировании книг в формат PDF и впечатлениями о технологии ClearScan, доступной в Adobe Acrobat начиная с версии 9.0. На мой взгляд, это замечательная технология, делающая (наконец-то!) формат PDF подходящим для отсканированного текста.
Фактически, при деструктивном сканировании (книга разрывается на листы и используется листовой сканер), процесс сканирования — чистки — перевода в PDF — OCR можно выполнить за тройку часов для книги среднего размера. (Надо сказать что у меня нет опыта в фотографировании книг, очевидно фотографирование тоже можно осуществить быстро, при надлежащем оборудовании, и таким образом избежать уничтожения бумажной книги.) Если же вы «стекольщик», то есть у вас достаточно терпения сканировать книгу на стекле сканера, сканирование, очевидно, займёт дольше.
Как сканирует начинающий
Если есть сканер, то хочется что-нибудь отсканировать! И слава Богу. Посмотрите на обилие электронных библиотек. Спасибо всем кто отсканировал и выложил это для других.
Сканеры сегодня продаются с пакетом программ, среди которых есть и программа по преобразованию в PDF. В теории (и в рекламных проспектах) это выглядит так: заложи в сканер листы, получи их на выходе в электронном виде, в формате PDF!
И это иногда правда. Есть большое количество разных бумаг (количеством 1, 2… 10 листов) с которыми я так и поступаю. А чего с ними чикаться? Видно — будет. А большее и не нужно. Но вот книга… да ещё для тех, кто любит книги… разве можно назвать получившуюся косую дрянь с полосами, пятнами, чёрными точками, с разорванным шрифтом книгой? Где же зарыта собака? Какую опцию надо выставить, какой рычажок покрутить, чтобы всё это стало похоже на оригинал?
В том-то и дело что нет такого одного рычажка. Есть четырёхступенчатый процесс, каждая ступень которого требует некоторых оптимальных решений от оператора. Пакет программ для сканера, работающий по типу «одним махом всех побивахом», скрывает этот четырёхступенчатый процесс, делая из него одну операцию: бумажный лист — электронный эквивалент. Но о том что на самом деле происходит что-то сложное, всё же можно догадаться. Например, сканер уже закончил сканировать, а компьютер ещё не готов продолжать; на нём открываются и закрываются какие-то программы; мигает лампочка доступа к жёсткому диску…
Чтобы отсканировать книгу качественно, надо самому пройтись по ступеням этого процесса: сканирование, чистка, перевод в нужный формат и распознавание текста (OCR).
1. Сканирование
Задача этой ступени перевести бумажные страницы книги в соответствующие им файлы в формате TIFF с разрешением 300dpi. Это разрешение достаточно для книжного текста обычного («читабельного») размера. Мелкий шрифт или желание передать мелкие детали иллюстраций может потребовать большего разрешения. Покопайтесь в настройках своего сканера. На выходе, вам нужно получить графические файлы, в формате TIFF. Один лист — один файл. И никаких многостраничных TIFF-ов (где в одном TIFF файле несколько страниц)! Никаких PDF-ов! Никаких OCR-ов (распознаваний текста)!
На этой ступени также нужно принять решение о сканировании книге в цвете (color) или в оттенках серого (grayscale). Обычно не рекомендуется сканировать книгу в строго чёрно-белом варианте (b&w), так как сканер должен будет тогда решать что делать чёрным, а что белым. Скажем, изгиб на странице может быть передан чёрным и создаст чёрные полосы и пятна, а ещё того хуже, эти пятна закроют чёрный же текст. Вычистить потом такое «чёрное на чёрном» невозможно. Если же пятно (полоса, другой дефект) серого (или другого, при цветном сканировании) цвета, а текст чёрного (отличного от дефекта) цвета, то дефект можно будет убрать на стадии чистки путём удаления из изображения цвета пятна. Бывает также, строго чёрно-белое сканирование утоньшает и разрывает линии и шрифт (то есть когда буква, скажем, «d» выглядит как «cl»). Поэтому, для качественного сканирования, представим что опции (b&w) не существует.
Для моего листового сканера, сканирование начинается с отрезания обложки. Обычный кухонный нож с коротким лезвием и удобной ручкой вполне подойдёт. Для мягкой обложки, нож просовывается между обложкой и первой страницей (при закрытой обложке) и обложка отрезается. Если у книги твёрдая обложка, то при открытой обложке из неё вырезается сама книга. Страницы потом либо отрываются по одной, либо отрезаются. Рваные края потом можно будет удалить с помощью программы на стадии чистки. Главное, чтобы рваные края не залезали на текст.
Пишу эти строки, а в голове звучит стихотворение Маршака:
У Скворцова Гришки
Жили-были книжки —
Грязные, лохматые,
Рваные, горбатые…
У меня есть книжки, ещё из детства, которые я люблю и не буду резать. Но часто приходится сканировать пособия, часто компьютерные, часто толстые, и макулатура — лучшее место для них. И времени своего на сканирование «на стекле» жаль тратить.
Ещё раз о базовых настройках сканера. Разрешение — 300dpi и цветовой режим «оттенки серого» (grayscale) или «цветной» (color). Формат файла — TIFF.
Измерив страницу книги в миллиметрах, можно задать длину и ширину. Конечно, «на стекле» это можно сделать лишь приблизительно, так как точно положить книгу на стекло невозможно. А листовой сканер будет засасывать листы с ровной стороны (либо сверху/снизу либо, если сбоку, надо положить ровной стороной) и тут всё будет точно вплоть до миллиметра. На своём листовом сканере я последнее время, из-за врождённой лени, выбираю опцию «улучшить текст» (text enhancement), которая «ужирняет» и «учерняет» текст и портит цветные иллюстрации (сгущает краски) и опцию «выравнять изображения» (deskew) так как ровные листы легче потом обработать. Но можно вообще никаких других опций кроме dpi и цвета не выбирать, и оставить всё остальное на стадию чистки.
2. Чистка
Задача этой ступени — получить на выходе файлы с чистыми, красивыми страницами в том же формате TIFF и в том же количестве. Это «набор» будущей электронной книги. Нечего и говорить, что обрабатывать нужно все (вернее почти все) изображения по группам, т. е. в «пакетном режиме» (batch processing). Кроме обложек и некоторых других неординарных страниц, возиться с каждым изображением страницы отдельно в графическом редакторе практически невозможно (представьте 700 страниц текста!) да и не нужно.
Для чистки, я пользуюсь программой ScanKromsator v 5.9. Её надо поискать в интернете. Я немного поплевался на пол из за её интерфейса, но это только сначала, пока не привыкнешь. Потом перестаёшь замечать причуды, и даже наоборот, отмечаешь как удобно сделать то или это.
Ссылки на описание этой программы:
• http://ru.wikipedia.org/wiki/ScanKromsator
• http://www.djvu-soft.narod.ru/kromsator/
• http://www.twirpx.com/file/394016/
Программа, особенно для начинающего, сложная, но всё же не такая сложная как, скажем, Photoshop. Есть также ScanTaylor, которая обещает быть проще, но я не пробовал. Какая бы программа не использовалась, нужно
• убрать наклон страниц (deskew)
• отрезать неровные края
• выравнять освещённость (убрать тени от неравномерной освещённости)
• убрать точки и другой мусор (despeckle)
• отдельно проверить/выправить иллюстрации (включая обложку)
online-knigi.com
Как сканировать в PDF формате
Для сканирования в формате PDF, как правило, подходят программы, идущие в комплекте с самим сканером. Если подобного программного обеспечения нет, или оно не устраивает, необходимо использовать сторонние программные продукты.

Как сканировать в PDF формате
ScanLite
Данный программный продукт является полностью бесплатным. Интерфейс достаточно простой.

Программный интерфейс ScanLite
Имя конечного документа и путь его сохранения указываются в первом окне интерфейса. Перед началом сканирования стоит указать его настройки.

Программный интерфейс настроек ScanLite
Имеется возможность выбора цветного, черно-белого режима сканирования, а также возможность регулирования качества выходного файла. При выборе опции «Вызвать диалог» перед началом сканирования появится окно драйвера сканера, для более точной настройки качества. Обратите внимание, что в зависимости от модели и производителя устройства, окно драйвера может выглядеть иначе.

Окно драйвера сканера
По завершении сканирования документ автоматически сохраняется по указанному пути.
WinScan2PDF
Данный программный продукт является полностью бесплатным. Интерфейс немногим сложнее, чем у ScanLite.

Программный интерфейс одностраничного режима WinScan2PDF
При нажатии на кнопку «Выбрать источник» появляется окно со списком подключенных сканеров, из которого нужно выбрать необходимое устройство.

Список сканеров
После выбора сканера, по нажатии кнопки «Сканировать», начинается процесс получения изображения, по завершении которого, программа предлагает указать путь сохранения файла.

Сохранение файла
Выбор качества конечного документа более широкий, по сравнению с предыдущей программой. Осуществить его можно через меню «Настройки», пункт «Качество PDF».

Выбор качества документа
WinScan2PDF позволяет создавать многостраничные документы. Для этого необходимо выбрать соответствующую опцию. Интерфейс программы изменится для представления постраничного вида документа.

Программный интерфейс многостраничного режима WinScan2PDF
Для поворота изображения страницы на 90 градусов нужно нажать кнопку «Показать изображение». В окне просмотра выбрать поворот в нужную сторону, и закрыть его. Для поворота изображения страницы на 180 градусов нужно выбрать отсканированное изображение, щелкнуть по нему правой кнопкой мыши и выбрать пункт «Rotate» в контекстном меню. Обратите внимание, смена миниатюры в интерфейсе WinScan2PDF будет довольно долгой, но на самом деле разворот страницы будет выполнен сразу.

Поворот страницы на 180 градусов

Окно просмотра страницы документа
Для смены положения страниц в конечном документе нужно выбрать отсканированное изображение, щелкнуть по нему правой кнопкой мыши и выбрать пункт «Вверх» или «Вниз».

Смена положения страниц документа
По завершении редактирования нужно нажать кнопку «Сохранить в PDF», процесс сохранения идентичен одностраничному режиму.
RiDoc
Программа является платной, и имеет пробный период 30 дней. Функционал шире, чем у рассмотренных ранее программ – есть возможность сохранения в Word, PDF, функция отправки конечного документа по электронной почте, возможность распознавания текста.

Программный интерфейс RiDoc
После выбора устройства и нажатия на кнопку «Сканер» открывается окно драйвера сканера, через которое производится настройка качества документа. Окончательное качество настраивается через меню «Склейка» в правой части окна. В этом же меню можно добавить водяной знак в документ PDF.

Меню «Склейка»
В программе предусмотрена возможность изменения яркости и контраста отсканированной страницы. В левой части экрана расположена галерея, со всеми сканами. При выборе определенной страницы и нажатии на пиктограмму «Яркость-Контрастность» открывается окно настройки изображения.

Настройки изображения
Для смены положения страниц в конечном документе достаточно перенести страницу мышкой на нужное положение. По окончании редактирования документа – нажать кнопку «Склейка», дождаться завершения процесса обработки и сохранить документ в PDF формате. При сохранении откроется диалоговое окно, где указывается имя файла, путь его сохранения и режим сохранения – несколько одностраничных документов («Сохранить группой файлов»), или многостраничный режим («Сохранить в multipage-режиме»).

Сохранение файла
VueScan
Программа является платной, и имеет пробный период 30 дней. Функционал наиболее широкий в плане регулировки качества, цвета, настроек кадрирования исходного изображения. Имеются три режима интерфейса – минимальные, настройки по умолчанию и детальные. Для сканирования в формате PDF используем режим по умолчанию.

Режим интерфейса VueScan по умолчанию, вкладка «На входе»
После сканирования каждой страницы имеется возможность ее отредактировать. Для поворота или зеркального отражения нужно выбрать соответствующий пункт в меню «Изображение». Для редактирования цветности изображение следует использовать вкладку «Цвет».

Вкладка «Цвет» и меню «Изображение»
Вкладка «На входе» позволяет регулировать параметры исходного документа. При выборе устройства необходимо указать режим сканирования – планшетный или автоподача. Настройки носителя устанавливаются по необходимости, разрешение при сканировании – в зависимости от требований к конечному документу. Вкладка «На выходе» нужна для регулировки конечного документа – формат и путь сохранения, а так же для выбора одностраничного или многостраничного режима.

Режим интерфейса VueScan по умолчанию, вкладка «На выходе»
При использовании одностраничного режима, файл создается в указанной директории автоматически. При многостраничном сканировании требуется подтверждение того, что отсканирована последняя страница.

Подтверждение окончания сканирования последней страницы документа
Заключение
Рассмотренные программные продукты дают возможность получать изображения в формате PDF. Сводная таблица для более оптимального выбора продукта представлена ниже.
| Лицензия | Бесплатная | Бесплатная | Платная | Платная |
| Русский язык | Да | Частично | Да | Да |
| Многостраничный режим | Нет | Да | Да | Да |
| Возможность редактирования документа | Нет | Да | Да | Да |
| Удобство интерфейса (от 1 до 5) | 5 | 3 | 4 | 4 |
| Дополнительные возможности | Нет | Нет | Распознание текста, отправка по электронной почте | Распознание текста, множественное кадрирование, восстановление цветности |
Видео — Как создать PDF
pc-consultant.ru
Работа со страницами PDF-документа
С помощью PDF-редактора вы можете изменять порядок страниц в PDF-документе, удалять ненужные или добавлять недостающие, а также добавлять пустые страницы в PDF-документ.
Как добавить страницы из файла...
- На панели инструментов нажмите кнопку
 .
. - Из выпадающего меню выберите Добавить из файла...
 Также вы можете выбрать пункт Добавить страницы из файла... в контекстном меню панели Страницы или из выпадающего меню при нажатии на кнопку
Также вы можете выбрать пункт Добавить страницы из файла... в контекстном меню панели Страницы или из выпадающего меню при нажатии на кнопку  .
. - В открывшемся диалоге выберите файл, который хотите добавить к открытому PDF-документу, или несколько файлов поддерживаемых форматов и при необходимости укажите номера необходимых страниц. Также можно указать, перед или после какой страницей необходимо добавить новые: перед первой страницей, перед текущей и др.
- Задайте настройки обработки изображений при добавлении страниц в документ, нажав кнопку Настройки....
- Нажмите кнопку Открыть.
В результате PDF-документ, созданный на основе выбранных файлов, будет добавлен к открытому в программе ABBYY FineReader документу.
Как отсканировать страницы и добавить их в PDF-документ...
Как добавить пустую PDF-страницу...
- На панели Страницы выделите страницу, до или после которой вы хотите добавить пустую страницу.
- В контекстном меню страницы раскройте пункт Добавить пустую страницу и выберите команду Перед текущей страницей или После текущей страницы.
Для добавления пустой страницы вы также можете использовать кнопку на панели инструментов >Добавить пустую страницу. В результате пустая страница будет добавлена после текущей.
Как изменить порядок страниц в документе...
- На панели Страницы выделите нужные страницы и перетащите их мышью в нужное место в документе.
Как повернуть страницу...
- На панели Страницы выделите одну или несколько страниц, в контекстном меню страницы или при нажатии на кнопку раскройте пункт Повернуть страницы и выберите одну из команд: Повернуть вправо, Повернуть влево.
Чтобы автоматически исправить ориентацию всех страниц, выберите Повернуть страницы > Исправить ориентацию всех страниц.
Как удалить страницу из PDF-документа...
- На панели Страницы выделите страницы, которые хотите удалить, и в контекстном меню выберите команду Удалить страницы... или нажмите клавишу Del.
Как создать PDF-документ из выбранных страниц...
- На панели Страницы выделите нужные страницы, затем в контекстном меню выберите команду Создать PDF из выбранных страниц
Созданный PDF-документ будет открыт в новом окне программы ABBYY FineReader.
Настройки обработки изображений при добавлении страниц
PDF-редактор предлагает различные настройки для обработки файлов изображений, которые позволяют улучшить исходное изображение и получить более точные результаты распознавания.
Вы можете задать параметры обработки изображений при сканировании бумажных документов и создании PDF-документа из файлов изображений.
- Качество изображений — качество изображений и размер полученного файла зависят от выбранного значения в выпадающем списке группы Качество изображений:
- Высокое качествоВыберите эту опцию, если вам важно сохранить качество изображения страницы или иллюстраций. Они будут сохранены с разрешением исходного изображения.
- СбалансированноеВыберите эту опцию, чтобы уменьшить размер документа по сравнению с исходным, но при этом сохранить достаточно высокое качество изображения страницы или иллюстраций.
- Небольшой размерВыберите эту опцию, если вы хотите получить PDF-документ небольшого размера. Это приведет к ухудшению качества изображения страницы или иллюстраций.
- Пользовательское... Выберите эту опцию для того, чтобы задать свои параметры сохранения изображения и иллюстраций. В открывшемся диалоговом окне Пользовательские настройки выберите необходимые значения и нажмите кнопку ОК.
- Распознавать текст на изображениях — отметьте эту опцию, чтобы добавить текстовый слой.
В результате получится документ с возможностью поиска по тексту, при этом внешний вид PDF-документа будет практически неотличим от оригинала.
- Сжимать изображения с помощью MRC (выберите языки распознавания ниже) — отметьте эту опцию, чтобы применить алгоритм сжатия изображений на основе технологии Mixed Raster Content (MRC) к распознанным страницам, который позволяет получить меньший размер файла без потери качества.
- Применить технологию ABBYY PreciseScan для сглаживания символов — отметьте эту опцию, чтобы применить технологию PreciseScan, разработанную компанией ABBYY. ABBYY PreciseScan сглаживает символы документа, в результате при увеличении масштаба страницы не возникает эффект пикселизации.
- Языки распознавания — для получения наилучшего результата необходимо правильно указать языки распознавания. Подробнее см. "Как учесть характеристики исходного документа".
help.abbyy.com
Как отсканировать документ из нескольких листов в один файл?
Как отсканировать документ из нескольких листов в один файл?
Проще всего отсканировать документ из нескольких листов в один файл воспользовавшись программой Bullzip PDF printer она очень проста в управлении и скачать ее можно перейдя по этой ссылке как именно можно отсканировать документ из нескольких листов в один файл смотрите в видео ролике представленном ниже.
есть разные виды фотошопов, которые несколько листов соединяют в один.наиболее распространенный Adobe Acrobat
При сканировании в настройках желательно выбрать формат pdf, а также поставить галочку на многостраничный файл, иногда еще такая функция называется многостраничный журнал. Ищите в настройках подобную опцию.
Но если отсканированы несколько страниц, а хочется, чтобы они были все соединены в один файл, то можно воспользоваться специальными онлайн-программами, например вот на этом сайте: https://smallpdf.com/ru/merge-pdf можно соединить несколько файлов ПДФ в один файл, занимает эта процедура не более 5 минут (все зависит от количества страниц, которые нужно соединить). Очень удобно, я периодически пользуюсь этим сервисом, он бесплатный и не требует регистрации на сайте и скачивать программу не нужно. Все делается онлайн. Быстро и удобно.
Вам необходимо изначально для решения данной проблемы, сделать два шага, а именно, выделить и сохранить те страницы которые вы отсканируете в рамках, многостраничного quot;PDFquot;.
Я как правило, осуществлял сие действие, в рамках расширения tif, но там все имеющуюся форматы, по сути, влияют только на объем файлов.
Все зависит от ПО, которое используете для сканирования. Но в целом, у всех программ для сканирования (особенно тех, что идут в комплекте к установочному ПО) есть такая функция quot;многостраничностьquot; (может называться несколько иначе, но суть та же). В таком режиме все отсканированные страницы будут сохранены в один файл.
Если вы будете сканировать в формате картинки, к примеру, JPEG, то в итоге каждый лист, который прошел через сканнер, будет считаться отдельным файлом. Лучше сразу выберите формат электронной книги, например, PDF, или если можно, то DJVU, EPUB и т. д.
А если уже отсканировали и получилось много файлов, их можно объединить через обычный редактор PDF - программу Adobe Acrobat.
Выделите и с охраните все отсканированные страницы как многостраничный PDF, если сохранять с расширением tif, то файл будет большим по объему, есть программа для распознавания текста ABBYY FineReader из которой можно не только сканировать и сохранять файлы, но и распознавать и править текст
Для начала нужно отсканировать все документы которые в дальнейшем нужно будет объединить в один лист. Отсканированные файлы будут сохранены скорее всего в формате JPEG в специальной папке. Далее в любом графическом редакторе нужно создать новый файл в размерах обычного листа А4 и все отсканированные документы перенести в этот новый файл и равномерно распределить по площади листа.
info-4all.ru